こんにちは!!!クライアントエンジニアの小林です。
今回はVGG16とCRAFTにGhostModuleを組み込んでみました。
作業環境
・windows 10
・visual studio code
・python 3.9.12
・pytorch lightning
概要
CRAFTのベースであるvgg_16bnと、それを元に構成されたUNetのCNNをGhostModuleに置き換えてみます。
モデル
各モデルについて軽く触れます。
詳細は論文や論文解説を確認してください。
VGG16
これ知らない人はいないと思いますが一応。
皆さんご存知の全結合を含むCNNを16層ことVGG16です。
bnはその名の通り畳み込みの後にbatch_normをしてる版です。
NNやDNNの勉強を始めたらチュートリアルかの如く登場してくれますよね。
しかも素晴らしいことに層を深くすると精度が上がる理由や、それの乖離現象である勾配消失などが分っかりやすくコレに詰まっています。
チュートリアルにもなるし応用研究にも使えるし、最強です。
CRAFT
Character Region Awareness for Text Detectionというタイトルで発表された文字領域の検出に特化したモデルです。
略称がCRAFTです。
vgg16_bnを元にU-Netを構成、それにより生成されたセグメンテーションを2値化、ラベリングすることで文字領域を検出しています。
本ブログで扱うCRAFTは論文内容とは異なり出力数を1つにしています。
GhostModule
ある意味で有名なファーウェイ。
そこの技術ラボであるHuawei Noah's Ark Labが開発したCNNです。
特徴は、特徴マップの冗長性に注目し、それらを線形変換することでフィルタ数を削減し最適化を図っています。
また、削除ではなく線形変換をすることでフィルタ数を削減しつつも精度を維持、場合によっては冗長性の解消によりオリジナルよりも高精度になることもあるそうです。
冗長性なんて気難しい単語を連発していますが、要は層が深いと似たような特徴マップがあるからそれらを線形補間で削減して無駄を減らしましょうということです。
無駄(似たような特徴)を減らした結果、ワンチャン精度も上がるかもよというおまけ付きです。
今回は2020年に発表されたV1を組み込んでいきます。
2022年にはV2の発表もありました。
数年に渡り同様の研究を継続できる企業体力とそれに応えられる技術者がいる環境っていいですね。
さすが自社OS作っちゃう化け物企業なだけはあります。
あれってAndroidベースでしたっけ、まぁどちらでもすごいことに変わりはないですが。
Ghost-VGG16-BN
さっそくCRAFTの学習と行きたいところですが、その前にGhostModuleを組み込んだvgg16_bnの学習済みモデルを作成します。
学習環境やハイパラなどは諸々pytorchの設定や実装を参考にしています。
モデル
GhostModuleでのpaddingはkernel_size//2とdw_size//2で決定されます。
vggで使用されているCNNはkernel_size=3, padding=1なため単に置き換えるだけでも互換性は保たれます。
models\ghost_module.py
import math import torch from torch import nn from torch import Tensor __all__ = [ "GhostModule", ] class GhostModule(nn.Module): def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True): super().__init__() self.oup = oup init_channels = math.ceil(oup / ratio) new_channels = init_channels*(ratio-1) self.primary_conv = nn.Sequential( nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False), nn.BatchNorm2d(init_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) self.cheap_operation = nn.Sequential( nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False), nn.BatchNorm2d(new_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) def forward(self, x:Tensor) -> Tensor: x1 = self.primary_conv(x) x2 = self.cheap_operation(x1) out = torch.cat([x1,x2], dim=1) return out[:, :self.oup, :, :]
models\ghost_vgg.py
from typing import Union import torch from torch import nn from torch import Tensor from .ghost_module import * __all__ = [ "make_layers", "cfgs", "GhostVGG", "GhostModule", ] def make_layers(cfg:list[Union[str,int]], batch_norm:bool=False) -> nn.Sequential: layers:list[nn.Module] = [] in_channels = 3 for v in cfg: if v == "M": layers += [nn.MaxPool2d(kernel_size=2, stride=2)] elif isinstance(v, int): conv2d = GhostModule(in_channels, v, kernel_size=3) if batch_norm: layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)] else: layers += [conv2d, nn.ReLU(inplace=True)] in_channels = v return nn.Sequential(*layers) cfgs: dict[str, list[Union[str, int]]] = { "A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"], "B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"], "D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"], "E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"], } class GhostVGG(nn.Module): def __init__(self, features:nn.Module, num_classes:int=1000, init_weights:bool=True, dropout:float=0.5) -> None: super().__init__() self.features = features self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) self.classifier = nn.Sequential( nn.Linear(512 * 7 * 7, 4096), nn.ReLU(True), nn.Dropout(p=dropout), nn.Linear(4096, 4096), nn.ReLU(True), nn.Dropout(p=dropout), nn.Linear(4096, num_classes), ) if init_weights: for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0) def forward(self, x: Tensor) -> Tensor: x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x
データセットのダウンロード
ImageNet-1Kを使用します。
公式とKaggleの両方で公開されていますが、今回はKaggleの方を使用します。
シンプルに申請が面倒だったのと、筆者はJAPAN SALES ONLYならぬSPEAK JAPANESE ONLYなのです。
ImageNetを使用する際の注意点としてあくまで研究目的で公開されており、商用利用は禁止されています。
以下のリンクからダウロードできます。
データセットのサイズは大体170GBぐらいです。


データセットの調整
データセットの中身を見てみるとtrainは分類ごとにフォルダわけされているのに対して、valとtestはごちゃ混ぜです。


pytorchの学習環境ではDataLoaderにImageFolderを使用しているのですが、これではvalとtestは適用できません。
そのためtrainと同様な階層にコンバートしちゃいます。
dataset_converter.py
from pathlib import Path import xml.etree.ElementTree as ET import shutil from concurrent.futures import ProcessPoolExecutor from tqdm import tqdm def func(xml_path:Path, src_dir:Path, dst_dir:Path) -> None: """画像ファイルの移動 Args: xml_path (Path): アノテーションが詰まったxmlファイル src_dir (Path): 移動元の画像が含まれるディレクトリ dst_dir (Path): 移動先のディレクトリ """ # folder, filename, source, size, segmented, object tree = ET.parse(xml_path) root = tree.getroot() text = root[5][0].text # 移動元と移動先のパスを作成 src_path = src_dir / f"{xml_path.stem}.JPEG" dst_path:Path = dst_dir / text / f"{xml_path.stem}.JPEG" # 移動先のディレクトリを作成 dst_path.parent.mkdir(parents=True, exist_ok=True) # 移動先にコピー shutil.copy(str(src_path), str(dst_path)) def my_app(image_dir:str, annotation_dir:str, output_dir:str): """trainと同様な構成に変換 Args: image_dir (str): test,valの画像ディレクトリ annotation_dir (str): test,valのアノテーションディレクトリ output_dir (str): 出力先 """ image_dir = Path(image_dir) annotation_dir = Path(annotation_dir) output_dir = Path(output_dir) # ファイル数が一致していない場合は欠損の可能性 assert len([True for i in image_dir.glob("*.JPEG")]) == len([True for i in annotation_dir.glob("*.xml")]), "not match length." # 書き込み速度に依存してプロセス数を適切にする with ProcessPoolExecutor(4) as executor: futures = [ executor.submit( func, xml_path, image_dir, output_dir, ) for xml_path in annotation_dir.glob("*.xml") ] for future in tqdm(futures): future.result() if __name__ == "__main__": my_app( r"E:\imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\val", r"E:\imagenet-object-localization-challenge\ILSVRC\Annotations\CLS-LOC\val", r"E:\imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\valid", )
| 引数名 | 内容 |
|---|---|
| image_dir | 画像のディレクトリを指定します。 例: imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\val\annotation_dir |
| annotation_dir | アノテーションのディレクトリを指定します。 例: imagenet-object-localization-challenge\ILSVRC\Annotations\CLS-LOC\val\output_dir |
| output_dir | 出力先のディレクトリを指定します。 例: imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\valid |
引数を指定してdataset_converter.pyを実行するとコンバートされます。
これですべてがステージフォルダ→分類フォルダ→画像ファイルという階層になり、ImageFolderに突っ込むだけで済みます。
DataLoaderの整備は地味に面倒なので助かりますね。
学習
はああぁぁぁ。。。1週間かかった。。。
ハイパラは以下の通りです。
| Parameter | Value |
|---|---|
| epoch | 90 |
| batch_size | 32 |
| optimizer | SGD |
| lr | 1.0e-2 |
| momentum | 0.9 |
| weight_decay | 1.0e-4 |
| scheduler | StepLR |
| lr_step_size | 30 |
| lr_gamma | 0.1 |
遷移はこんな感じです。






最終的な精度比較です。
testで測るの面倒というか忘れたのでvalidの最終結果です。
| model | acc@1 | acc@5 |
|---|---|---|
| vgg16_bn | 73.36 | 91.516 |
| ghost_vgg16_bn | 67.93 | 88.44 |
論文ではGhostNetでCIFAR-10に対して有効性を示していましたが、GhostModule単体だとイマイチなんでしょうか。
思ったほど高くなかった。
精度にだけ着目するとオリジナルより劣りますが、設計を維持したまま軽量化できるという汎用性を考慮したら十分な結果なのかもしれません。
それにCRAFTでは、vgg16_bnの重みを足がかかりに学習を進めるだけで固定化するわけではないので、一旦良しとします。
というより追加で1週間の学習はイヤなのです。
学習済みモデル
冒頭でも触れたとおりImageNetが商用利用不可なため、学習済みモデルにはCC BY-NC 4.0を適用しています。
ファイルサイズが500 MBほどありますが94%はclassifierが占めています。
商用利用したい場合は、以下に学習コードを貼っているので商用利用可能なデータセットで再学習してください。
先ほども触れましたがImageNet-1K規模だと3090Tiで1週間弱ほどの時間を要します。なげぇのよ。
学習コード
時間かかりすぎて二度と学習してやるものかと思ったのでパラメータ類は全て決め打ちになっています。
ちょっと使いづらいかもしれません。
presets.py
import torch from torchvision.transforms import autoaugment, transforms from torchvision.transforms.functional import InterpolationMode __all__ = [ "ClassificationPresetTrain", "ClassificationPresetEval", ] class ClassificationPresetTrain: def __init__( self, *, crop_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), interpolation=InterpolationMode.BILINEAR, hflip_prob=0.5, auto_augment_policy=None, ra_magnitude=9, augmix_severity=3, random_erase_prob=0.0, ): trans = [transforms.RandomResizedCrop(crop_size, interpolation=interpolation)] if hflip_prob > 0: trans.append(transforms.RandomHorizontalFlip(hflip_prob)) if auto_augment_policy is not None: if auto_augment_policy == "ra": trans.append(autoaugment.RandAugment(interpolation=interpolation, magnitude=ra_magnitude)) elif auto_augment_policy == "ta_wide": trans.append(autoaugment.TrivialAugmentWide(interpolation=interpolation)) elif auto_augment_policy == "augmix": trans.append(autoaugment.AugMix(interpolation=interpolation, severity=augmix_severity)) else: aa_policy = autoaugment.AutoAugmentPolicy(auto_augment_policy) trans.append(autoaugment.AutoAugment(policy=aa_policy, interpolation=interpolation)) trans.extend( [ transforms.PILToTensor(), transforms.ConvertImageDtype(torch.float), transforms.Normalize(mean=mean, std=std), ] ) if random_erase_prob > 0: trans.append(transforms.RandomErasing(p=random_erase_prob)) self.transforms = transforms.Compose(trans) def __call__(self, img): return self.transforms(img) class ClassificationPresetEval: def __init__( self, *, crop_size, resize_size=256, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), interpolation=InterpolationMode.BILINEAR, ): self.transforms = transforms.Compose( [ transforms.Resize(resize_size, interpolation=interpolation), transforms.CenterCrop(crop_size), transforms.PILToTensor(), transforms.ConvertImageDtype(torch.float), transforms.Normalize(mean=mean, std=std), ] ) def __call__(self, img): return self.transforms(img)
utils.py
import torch __all__ = [ "accuracy", ] def accuracy(output, target, topk=(1,)): """Computes the accuracy over the k top predictions for the specified values of k""" with torch.inference_mode(): maxk = max(topk) batch_size = target.size(0) if target.ndim == 2: target = target.max(dim=1)[1] _, pred = output.topk(maxk, 1, True, True) pred = pred.t() correct = pred.eq(target[None]) res = [] for k in topk: correct_k = correct[:k].flatten().sum(dtype=torch.float32) res.append(correct_k * (100.0 / batch_size)) return res
train.py
import torch from torch import Tensor from torch import optim from torch.nn import functional as F from torch.utils.data import DataLoader from torchvision.datasets import ImageFolder from torchvision.transforms.functional import InterpolationMode import pytorch_lightning as pl from pytorch_lightning.loggers import TensorBoardLogger from pytorch_lightning.callbacks import ModelCheckpoint, LearningRateMonitor import warnings from pytorch_lightning.utilities.warnings import PossibleUserWarning # num_workers増やせ警告を非表示 warnings.simplefilter("ignore", PossibleUserWarning) from models import * from presets import * from utils import * class ImageNetDataModule(pl.LightningDataModule): def __init__(self): super().__init__() def setup(self, stage:str) -> None: self.train_dataset = ImageFolder( r"E:\imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\train", ClassificationPresetTrain( crop_size=224, interpolation=InterpolationMode.BILINEAR, auto_augment_policy=None, random_erase_prob=0.0, ra_magnitude=9, augmix_severity=3, ), ) self.valid_dataset = ImageFolder( r"E:\imagenet-object-localization-challenge\ILSVRC\Data\CLS-LOC\valid", ClassificationPresetEval( crop_size=224, resize_size=256, interpolation=InterpolationMode.BILINEAR, ), ) def train_dataloader(self): return DataLoader(self.train_dataset, batch_size=64, pin_memory=True, num_workers=2, shuffle=True) def val_dataloader(self): return DataLoader(self.valid_dataset, batch_size=64, pin_memory=True, num_workers=2, shuffle=False) class GhostVGG16Module(pl.LightningModule): def __init__(self): super().__init__() self.model = GhostVGG(make_layers(cfgs["D"], True)) def forward(self, x:Tensor): return self.model(x) def training_step(self, batch:list[Tensor, Tensor], batch_idx:int): image, target = batch output = self(image) loss = F.cross_entropy(output, target, label_smoothing=0.0) acc1, acc5 = accuracy(output, target, topk=(1, 5)) return {"loss":loss, "acc1":acc1, "acc5":acc5} def training_epoch_end(self, outputs) -> None: train_loss = torch.stack([x["loss"] for x in outputs]).mean() train_acc1 = torch.stack([x["acc1"] for x in outputs]).mean() train_acc5 = torch.stack([x["acc5"] for x in outputs]).mean() self.log("train_loss", train_loss) self.log("train_acc1", train_acc1) self.log("train_acc5", train_acc5) def validation_step(self, batch:list[Tensor, Tensor], batch_idx:int): image, target = batch output = self(image) loss = F.cross_entropy(output, target, label_smoothing=0.0) acc1, acc5 = accuracy(output, target, topk=(1, 5)) return {"val_loss":loss, "val_acc1":acc1, "val_acc5":acc5} def validation_epoch_end(self, outputs): valid_loss = torch.stack([x["val_loss"] for x in outputs]).mean() valid_acc1 = torch.stack([x["val_acc1"] for x in outputs]).mean() valid_acc5 = torch.stack([x["val_acc5"] for x in outputs]).mean() self.log("val_loss", valid_loss) self.log("val_acc1", valid_acc1) self.log("val_acc5", valid_acc5) def configure_optimizers(self): optimizer = optim.SGD( self.parameters(), lr=1e-02, momentum=0.9, weight_decay=1e-04, nesterov=False, ) scheduler = optim.lr_scheduler.StepLR( optimizer, step_size=30, gamma=0.1, ) return [optimizer], [scheduler] if __name__ == "__main__": torch.set_float32_matmul_precision("high") pl.seed_everything(522) datamodule = ImageNetDataModule() model = GhostVGG16Module() logger = TensorBoardLogger( save_dir=r"E:\ReinVision\ghost-vgg", name="log_logs", default_hp_metric=False, ) callbacks = [ LearningRateMonitor( log_momentum=False, ), ModelCheckpoint( monitor="val_loss", filename="checkpoint-{epoch}-{val_loss:.8f}", save_top_k=3, mode="min", save_last=True, ), ] trainer = pl.Trainer( max_epochs=90, callbacks=callbacks, logger=logger, accelerator="gpu", devices=[0], ) trainer.fit( model=model, datamodule=datamodule, )
Ghost-CRAFT
ghost_vgg16_bnの学習済みモデルも用意できたことなのでGhostCRAFTの学習に進みたいと思います。
モデル
vggと同様に置き換えるだけです。
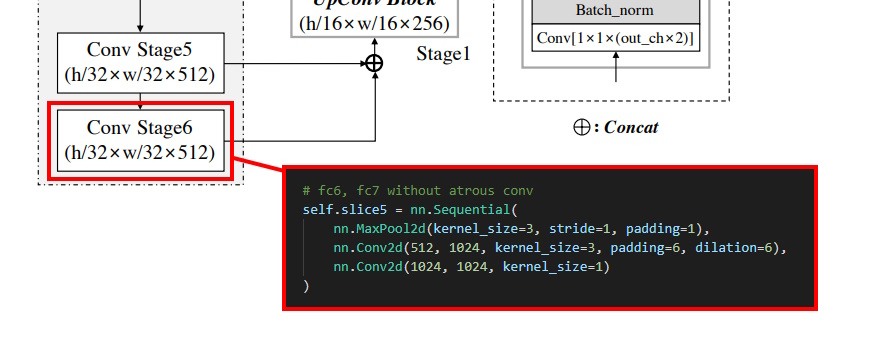
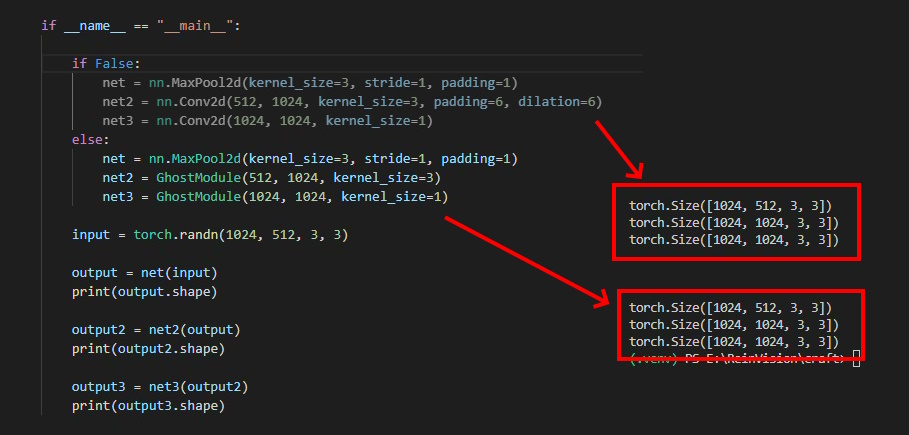
予定ではConvStage6は少し改修しないとダメかなと思っていたのですが、出力層を見た限りでは特に問題なかったです。
というよりGhostModuleは膨張引数取ってないんですよね。
少し不安ではありますがとりあえず試してみましょう。
models\ghost_vgg16_bn.py
from collections import namedtuple import torch.nn as nn from torch import Tensor from .ghost_vgg import * __all__ = [ "ghost_vgg16_bn", "init_weights", "GhostModule", ] def init_weights(modules) -> None: for m in modules: if isinstance(m, nn.Conv2d): nn.init.xavier_uniform_(m.weight.data) if m.bias is not None: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() elif isinstance(m, nn.Linear): m.weight.data.normal_(0, 0.01) m.bias.data.zero_() class ghost_vgg16_bn(nn.Module): def __init__( self, pretrained:bool=True, freeze:bool=True, ): super().__init__() vgg_pretrained_features = GhostVGG.load_from_pretrained( r"E:\ReinVision\ghost-vgg\log_logs\version_1\checkpoints\ghost_vgg16_bn.pth", ).features self.slice1 = nn.Sequential() self.slice2 = nn.Sequential() self.slice3 = nn.Sequential() self.slice4 = nn.Sequential() self.slice5 = nn.Sequential() # conv2_2 for x in range(12): self.slice1.add_module(str(x), vgg_pretrained_features[x]) # conv3_3 for x in range(12, 19): self.slice2.add_module(str(x), vgg_pretrained_features[x]) # conv4_3 for x in range(19, 29): self.slice3.add_module(str(x), vgg_pretrained_features[x]) # # conv5_3 for x in range(29, 39): self.slice4.add_module(str(x), vgg_pretrained_features[x]) # fc6, fc7 without atrous conv self.slice5 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), GhostModule(512, 1024, kernel_size=3), GhostModule(1024, 1024, kernel_size=1), ) if not pretrained: init_weights(self.slice1.modules()) init_weights(self.slice2.modules()) init_weights(self.slice3.modules()) init_weights(self.slice4.modules()) # no pretrained model for fc6 and fc7 init_weights(self.slice5.modules()) if freeze: for param in self.slice1.parameters(): # only first conv param.requires_grad = False def forward(self, x:Tensor) -> Tensor: h = self.slice1(x) h_relu2_2 = h h = self.slice2(h) h_relu3_2 = h h = self.slice3(h) h_relu4_3 = h h = self.slice4(h) h_relu5_3 = h h = self.slice5(h) h_fc7 = h vgg_outputs = namedtuple("VggOutputs", ["fc7", "relu5_3", "relu4_3", "relu3_2", "relu2_2"]) out = vgg_outputs(h_fc7, h_relu5_3, h_relu4_3, h_relu3_2, h_relu2_2) return out
models\ghost_craft.py
import torch import torch.nn as nn import torch.nn.functional as F from torch import Tensor from .ghost_vgg16_bn import * __all__ = [ "GhostCRAFT", ] class double_conv(nn.Module): def __init__( self, in_channels:int, mid_channels:int, out_channels:int, ): super().__init__() self.conv = nn.Sequential( GhostModule(in_channels + mid_channels, mid_channels, kernel_size=1), nn.BatchNorm2d(mid_channels), nn.ReLU(inplace=True), GhostModule(mid_channels, out_channels, kernel_size=3), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), ) def forward(self, x:Tensor): x = self.conv(x) return x class GhostCRAFT(nn.Module): def __init__( self, pretrained:bool=False, freeze:bool=False, ): super().__init__() # Base network self.basenet = ghost_vgg16_bn(pretrained, freeze) # U network self.upconv1 = double_conv(1024, 512, 256) self.upconv2 = double_conv(512, 256, 128) self.upconv3 = double_conv(256, 128, 64) self.upconv4 = double_conv(128, 64, 32) num_class = 1 # region only self.conv_cls = nn.Sequential( GhostModule(32, 32, kernel_size=3), nn.ReLU(inplace=True), GhostModule(32, 32, kernel_size=3), nn.ReLU(inplace=True), GhostModule(32, 16, kernel_size=3), nn.ReLU(inplace=True), GhostModule(16, 16, kernel_size=1), nn.ReLU(inplace=True), GhostModule(16, num_class, kernel_size=1), ) init_weights(self.upconv1.modules()) init_weights(self.upconv2.modules()) init_weights(self.upconv3.modules()) init_weights(self.upconv4.modules()) init_weights(self.conv_cls.modules()) def forward(self, x:Tensor): # Base network sources = self.basenet(x) """ U network """ y = torch.cat([sources[0], sources[1]], dim=1) y = self.upconv1(y) y = F.interpolate(y, size=sources[2].size()[2:], mode="bilinear", align_corners=False) y = torch.cat([y, sources[2]], dim=1) y = self.upconv2(y) y = F.interpolate(y, size=sources[3].size()[2:], mode="bilinear", align_corners=False) y = torch.cat([y, sources[3]], dim=1) y = self.upconv3(y) y = F.interpolate(y, size=sources[4].size()[2:], mode="bilinear", align_corners=False) y = torch.cat([y, sources[4]], dim=1) y = self.upconv4(y) y = self.conv_cls(y) return y
models\gaussian.py
import numpy as np import math import cv2 __all__ = [ "region_to_bboxes", "GaussianGenerator", ] def region_to_bboxes( region:np.ndarray, binary_threshold:float, char_size:int, char_threshold:float, ) -> list[tuple[int, int, int, int]]: """regionマップからbbox抽出 Args: region (np.ndarray): _description_ binary_threshold (float): 2値化の閾値 char_size (int): 文字と判定するサイズ char_threshold (float): _description_ Returns: list[tuple[int]]: _description_ """ _, text_score = cv2.threshold(region, binary_threshold, 1.0, cv2.THRESH_BINARY) text_score = np.clip(text_score * 255, 0, 255).astype(np.uint8) nlabels, labels, stats, _ = cv2.connectedComponentsWithStats(text_score, connectivity=4) bboxes:list[tuple[int, int, int, int]] = [] for k in range(1, nlabels): x, y, w, h, size = stats[k].tolist() # size filtering if size < char_size: continue # thresholding if np.max(region[labels==k]) < char_threshold: continue # make segmentation map segmap = np.zeros(region.shape, dtype=np.uint8) segmap[labels==k] = 255 niter = int(math.sqrt(size * min(w, h) / (w * h)) * 2) # boundary check xmin, ymin = max(0, x - niter), max(0, y - niter) xmax, ymax = min(x + w + niter + 1, region.shape[1]), min(y + h + niter + 1, region.shape[0]) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1 + niter, 1 + niter)) segmap[ymin:ymax, xmin:xmax] = cv2.dilate(segmap[ymin:ymax, xmin:xmax], kernel) # make box np_contours = np.roll(np.array(np.where(segmap!=0)), 1, axis=0).transpose().reshape(-1, 2) rectangle = cv2.minAreaRect(np_contours) box:np.ndarray = cv2.boxPoints(rectangle) * 2 # CRAFTの仕様上スケールは2で固定している # convert format lt, rt, lb, rb = box.astype(np.int32).tolist() xmin, ymin = min(lt[0], lb[0]), min(lt[1], rt[1]) xmax, ymax = max(rt[0], rb[0]), max(lb[1], rb[1]) bboxes.append((xmin, ymin, xmax, ymax)) return bboxes class GaussianGenerator: def __init__( self, ksize:tuple[int, int]=(64, 64), dratio:float=5.0, ): self.ksize = ksize self.dratio = dratio self.gaussian2d = self.isotropic_gaussian_heatmap(ksize=ksize, dratio=dratio) def isotropic_gaussian_heatmap( self, ksize:tuple[int, int]=(32, 32), dratio:float=3.0, ) -> np.ndarray: """_summary_ Args: ksize (tuple[int], optional): _description_. Defaults to (32, 32). dratio (float, optional): _description_. Defaults to 3.0. Returns: np.ndarray: _description_ """ w, h = ksize half_w, half_h = w * 0.5, h * 0.5 half_max = max(half_w, half_h) gaussian2d_heatmap = np.zeros((h, w), np.uint8) for y in range(h): for x in range(w): distance_from_center = np.linalg.norm(np.array([y - half_h, x - half_w])) distance_from_center = dratio * distance_from_center / half_max scaled_gaussian_prob = math.exp(-0.5 * (distance_from_center ** 2)) gaussian2d_heatmap[y, x] = np.clip(scaled_gaussian_prob * 255, 0, 255) return gaussian2d_heatmap def perspective_transform( self, image:np.ndarray, bbox:tuple[int, int, int, int], ) -> np.ndarray: """射影変換 Args: image (np.ndarray): _description_ bbox (tuple[int]): (xmin, ymin, xmax, ymax) Returns: np.ndarray: _description_ """ xmin, ymin, xmax, ymax = bbox h1, w1 = image.shape h2, w2 = (ymax - ymin, xmax - xmin) pts1 = np.array([[0, 0], [w1, 0], [w1, h1], [0, h1]], dtype=np.float32) pts2 = np.array([[0, 0], [w2, 0], [w2, h2], [0, h2]], dtype=np.float32) # 画像をbboxサイズに射影変換 M = cv2.getPerspectiveTransform(pts1, pts2) image = cv2.warpPerspective(image, M, (w2, h2), flags=cv2.INTER_LINEAR) return image def __call__( self, image_size:tuple[int, int], bboxes:list[tuple[int, int, int, int]], ) -> np.ndarray: """_summary_ Args: image_size (tuple[int]): _description_ bboxes (list[tuple[int]]): _description_ Returns: np.ndarray: _description_ """ # blend:addな挙動をするので16bitにしている image = np.zeros(image_size, dtype=np.uint16) g2dheatmap = self.gaussian2d.copy() for bbox in bboxes: # ヒートマップをbboxサイズに変換 warped = self.perspective_transform(g2dheatmap, bbox) xmin, ymin, xmax, ymax = bbox image[ymin:ymax, xmin:xmax] += warped return np.clip(image, 0, 255).astype(np.uint8)
学習
遷移はこんな感じです。


| 線の色 | モデル |
|---|---|
| 橙色 | CRAFT (epoch=10) |
| 朱色 | GhostCRAFT (epoch=10) |
| 紺色 | GhostCRAFT (epoch=20) |
エポック数が同じ場合は劣化が目立ちますね。
これはvggの結果からなんとなく予想は付いていました。
とはいえエポック数を増やすと本家と同程度にまで落ち着くので高止まりしている訳ではなさそうです。
精度比較
ADVのゲーム画面をスクショした画像に含まれるテキストを検出できるかで精度を測ってみます。
算出方法は(検出数-誤検出) / 画像に含まれる総文字数としています。
また、文字認識で使用されるようなプリプロ/ポストプロセスはオフにして純粋なモデル性能に頼った検出をしています。
結果は以下の通りです。
| モデル | 精度 |
|---|---|
| CRAFT (epoch=10) | 171,248/171,309 (99.9644%) |
| GhostCRAFT (epoch=10) | 170,691/171,309 (99.6392%) |
| GhostCRAFT (epoch=20) | 171,262/171,309 (99.9726%) |
本家には劣りますね。
劣りはするのですが、そもそものvgg16_bnの精度差分があるという条件不一致な計測なのであんまり信用できる値ではないのが不満点です。
少しモヤモヤが残りますが、学習の調整幅次第では本家と同様の精度を出せることも分かりました。
パラメータ数も20.8 Mから10.4 Mに、学習済みモデルのファイルサイズも79.3 MBから40.0 MBほどになり、軽量化効果に対する精度維持能力も十分に体験できました。
GhostModuleさん、もといHuawei Noah's Ark Labさん、すごいです。
おわり!!!
お疲れさまでした!!!
線形補間という単純なアプローチとは思えないほどの効果で正直驚きました。
純粋な最適化効果だけであればMobileNetを選択する方がいいと思うのですが、アッチは設計変更が必要なのでローコストで選ぶならGhostModuleといった感じでしょうか。
CNNの勉強中に見つけた面白そうな技術だったので試してみましたが、やっぱり面白かったです。
良き寄り道が出来て満足です。