こんにちは!!!クライアントエンジニアの小林です。
今回はニューラルネットワークの万能近似定理を利用してベースカラーとシャドウカラーの可逆性が求められないか検証してみます。
作業環境
・windows 10
・visual studio 2022
・visual studio code
・PyTorch Lightning
・Unreal Engine 5.2 (エンジン改造済み)
概要
UnrealEngineのディファードレンダリングでは、ざっくりとですが以下の計算でシーンカラーが求められています。
前方がメインライトパス、後方がスカイライトパスです。
((DiffuseColor * dot(MainLightDir, WorldNormal)) * (MainLightColor * Shadow)) + (SkyLightColor * dot(SkyLightDir, UpDir) * DiffuseColor)


このような計算故にシャドウカラーはほとんどスカイライトパスによって決定されます。
リアル調であればこの計算方法でも概ね問題ないと思いますが、トゥーン調となると問題が出てきます。
その問題点とはスカイライトパスの影響が強すぎて好みの色味が出ないということです。
そのためトゥーン調では以下の計算がよく使われるイメージがあります。
lerp(DiffuseColor, ShadowColor, NoL > Threshold ? 1.0 : 0.0)
シャドウカラーをカラーやテクスチャで指定し、それをメインライトパスで塗ることで、スカイライトパスでの影響度を中和できます。
スカイライトは標準計算と同様だったり、法線影響を無視したりなど、プロジェクト依存だったりです。
トゥーン表現の陰影色をカラーやテクスチャで指定するこの方法ですが1点だけデメリットがあります。
それは調整に人的コストが掛かることです。
製品であればこのコストを掛けるべきだと思うのですが趣味の個人開発では例外なこともあります。
それは開発者の絵の知識が微妙で且つものぐさである場合です。
そう、筆者のことです。
こういう時はベースカラーやディフューズカラーからシャドウカラーの計算を行うことで解消できます。
これ自体は色空間に分解して係数調整をすることで割と簡単にできます。
しかしこの方法にも問題はあるのです。
それは再現しようとしている絵がアニメ絵である場合、人間が色付けをしたり、後処理を入れているなどの複数の要因が重なり、ベースカラーとシャドウカラーの可逆性を見つけることが困難であることです。
とはいえ時間をかければ可逆性の手掛かりを掴めることもあります。
あるのですが結局は時間をかけないといけないのです。
ものぐさな筆者はこれすら面倒でした。
いちおう1時間ほど格闘しましたが手掛かりすら掴めずに諦めました。
そんな時にふと思ったのです。
深層学習に万能近似定理、関数近似あったなと。
深層学習モデルにベースカラーとシャドウカラーを元に学習させればShadowColor = f(SceneColor)という関数が作れるのでは?と思ったわけです。
万能近似定理とは
ニューラルネットワークには、どのような関数も近似して表現できる万能近似定理というものがあります。
筆者は難しい話ができるほどの頭は持ち合わせていないので実装を元に追っていきます。
例としてexp関数の関数近似を作成します。
まずモデル設計は、シンプルにLinearとReLUです。
この程度であればReLUも要らないと思いますが、あって困るものではないので突っ込んでおきます。
class Model(nn.Module): def __init__(self): super().__init__() self.seq = nn.Sequential( nn.Linear(1, 32), nn.ReLU(), nn.Linear(32, 64), nn.ReLU(), nn.Linear(64, 1), ) def forward(self, x:Tensor) -> Tensor: x = self.seq(x) return x
データセットは入力値とラベル値がペアのものを使います。この場合はxが入力値で、yがexp(x)の計算結果、つまりラベル値です。
このexpをsinやcosに変えることでそれらの関数近似を作ることもできます。
def create_dataset(self, n:int) -> TensorDataset: x = np.random.random(n) y = np.exp(x) x = x.reshape(n, 1) y = y.reshape(n, 1) x = torch.FloatTensor(x) y = torch.FloatTensor(y) return TensorDataset(x, y)
損失はMSELossを使います。
def training_step(self, batch:list[Tensor, Tensor], batch_index:int): image, label = batch output = self(image) loss = F.mse_loss(output, label) self.log_outputs["train_loss"].append(loss.tolist()) return {"loss":loss}
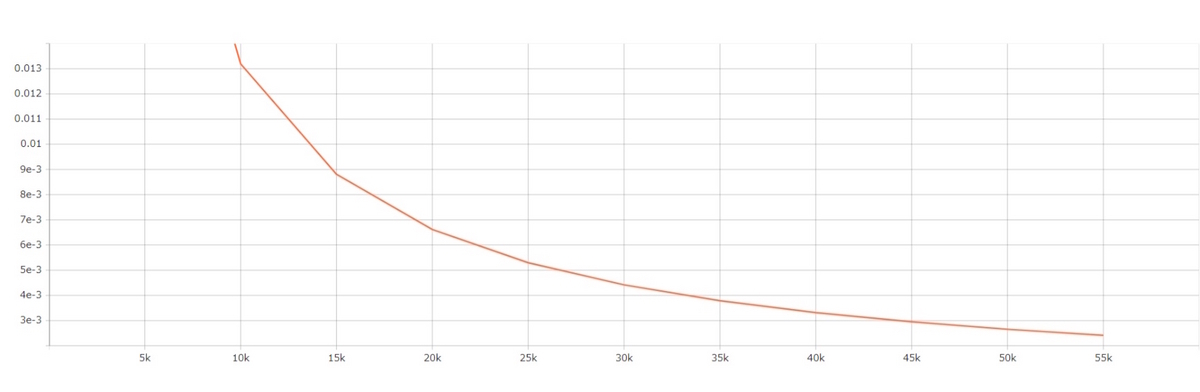
10エポックほど学習させた場合の損失の推移です。
たったこれだけですが、収束しているのが確認できますね。
最後にモデルの出力結果をプロットしてみます。
青線がラベルデータであるexp関数、橙線がexp関数の関数近似です。
関数近似という名のとおり、よく似た結果になってますね。
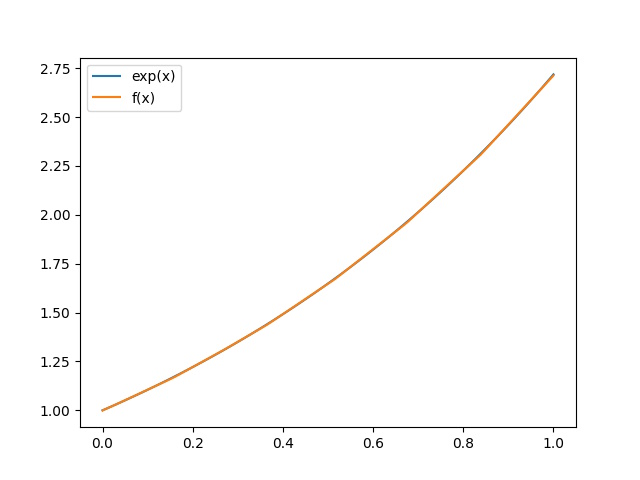
ちなみにあえて学習データは入力値を0.0〜1.0に限定しました。
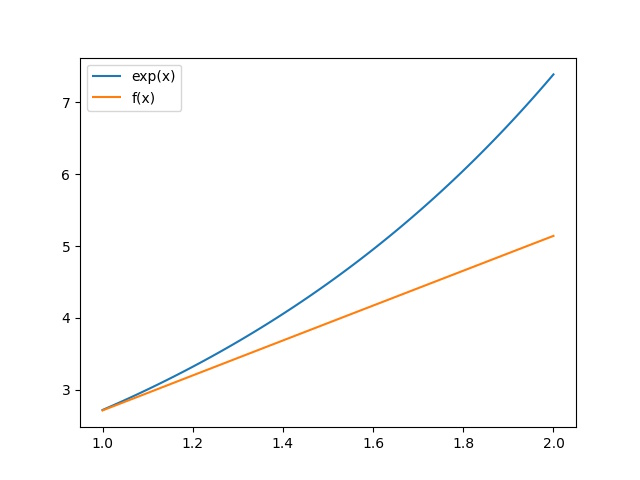
試しに学習してない範囲である1.0〜2.0の出力結果をプロットしてみましょう。
結果はこのように近似していません。
定理という小難しい単語が付いているだけに内容自体は深いのですが、
実装と出力結果だけに注目すると意外とすんなり現象を理解できると思います。
方針
GNNとかもありますが、思い付きからの脊髄反射的なコーディングをしているのでLinearとReLUのみで構成します。
損失関数はMSELossを使用します。
データセットはベースカラーとシャドウカラーのペアを作成し、それを使用します。
データセットの作り方
目指している絵作りからベースカラーとシャドウカラーがペアになったサンプルを用意します。


ベースカラーとシャドウカラー画像に含まれるカラーで、すべての組み合わせを作ります。
画像を例にするとベースカラーには47色、シャドウカラーには19色が含まれており、これらをすべて組み合わせると893のサンプル数になります。

理想的なのはカラー画像の中央値を計算、それでペアを作成することなのですが、この方法では画像をそれなりに用意しないとサンプル不足に陥ります。
サンプルを集めればいいじゃないと思うかもしれませんが筆者はものぐさです。
そのため雑にサンプル数をカサ増しできる方法を取ったのです。
懸念点としては近しいカラーで異なる組み合わせが多く存在するため、入力値とラベル値の関係性に矛盾が生じている可能性があることです。このあたりは賢いニューラルネットワークが解決してくれることをを信じています。(丸投げ)
色空間による入力データの比較
モデルは3入力3出力です。
その入力値に適している色空間を探します。
探した方としてはバッチサイズ大きめちゃちゃっと学習を進めて収束が一番早いものを使用するという単純な比較で行います。
試してみる色空間はRGB、HSV、LABの3種類です。
筆者はLab推しです。
Lab色空間による明るさ調整は直感的に近いというのが推し理由です。
計算量が多いというデメリットもありますが。
それでは結果を確認します。
橙線がRGB、青線がHSV、赤線がLABの順です。


HSVの収束が早いことがわかりました。
筆者の推しであるLabさんは残念な結果でした。
学習結果
シーンカラーを入力に推論を行い、その結果とラベル値であるシャドウカラーでMSELossを求めます。
3パターンほど中間層を試してみました。
Linearの後にはReLUをぶち込んでいます。
そこまで複雑な表現ではないので層を深くする必要もないとは思いますが、興味本位で深くしてみます。
| 線の色 | ノード数 |
|---|---|
| 青 | (3,32) - (32,64) - (64,3) |
| 赤 | (3,32) - (32,64) - (64,128) - (128,3) |
| 水 | (3,64) - (64,128) - (128,256) - (256,3) |


こんなんでも層を深くした方が損失は小さくなるのですね。
むしろ局所解を生みそうで怖いけど。
推論結果
左から入力値であるシーンカラー画像の中央値、ラベル値であるシャドウカラー画像の中央値、出力されたシャドウカラーの順です。
肌色と薄ピンク系が明らかに失敗していますが、それ以外は割とそれっぽいですね。
局所解でも取ったのでしょうか。
学習データが少ないので過学習の線もありそうですが。

テクスチャを作成してみた
次にディフューズテクスチャからシャドウカラーテクスチャを生成してみました。
学習データに含まれる原色系は割と理想的な変換結果ですが、それ以外のカラーやブレンド箇所が絶望的ですね。


方針改め
テクスチャを生成することで問題点が透けてきました。
この結果を踏まえて1回だけ改修をして終わりにしたいと思います。
あくまで気分転換で始めたことなのであまり詰めすぎるのはちゃうなぁという気持ちです。
まずはデータセットの作成方法を変更します。
画像に含まれるすべてのカラーで組み合わせはやはり悪手だったので、画像の中央値を使う形に変更します。
それに伴いサンプル数は90から406に増やしました。
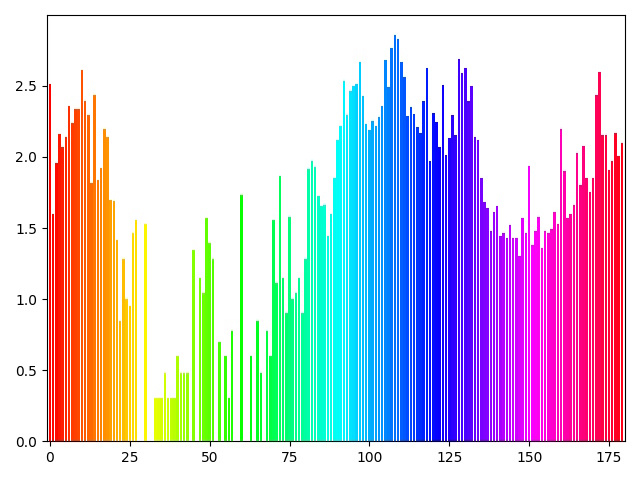
HSVで散布図をプロットしてみました。
左が90サンプル、右が406サンプルです。
90サンプルよりは偏りが解消されている気がします。


サンプル集めをする際に色相グラフで可視化しながらやったのですが、どうしてもその作品でよく出る色味がある都合上、なかなか難しいですね。グラフはlog10で均しています。緑系が少ないですね。
次に処理層を1層に変更しました。
複雑な表現ができるという反面、単純な結果を求めたい場合には局所的過ぎるなぁという気がしたので。
3 > 128 > 256 > 3に変更です。
あとはデータセットを作成する際に、カサ増し用にlerp(BaseColorの中央値、ShadowColorの中央値、間隔)ということをしていたのですが、この間隔が狭すぎると、これまた局所的な結果を求めすぎていて色補間の精度がむしろ悪化するということも分かりました。
これらを元に改善した結果がこちらです。
改善前のような明らかな失敗がほぼない気がします。

テクスチャの生成結果です。



割とそれっぽくなりましたね。
なんかもうひとひねりぐらいしたら行けそうな雰囲気もありつつですが、
あくまで気分転換で始めたことなのでこのくらいで止めておきます。
普通に勉強にもなりました。
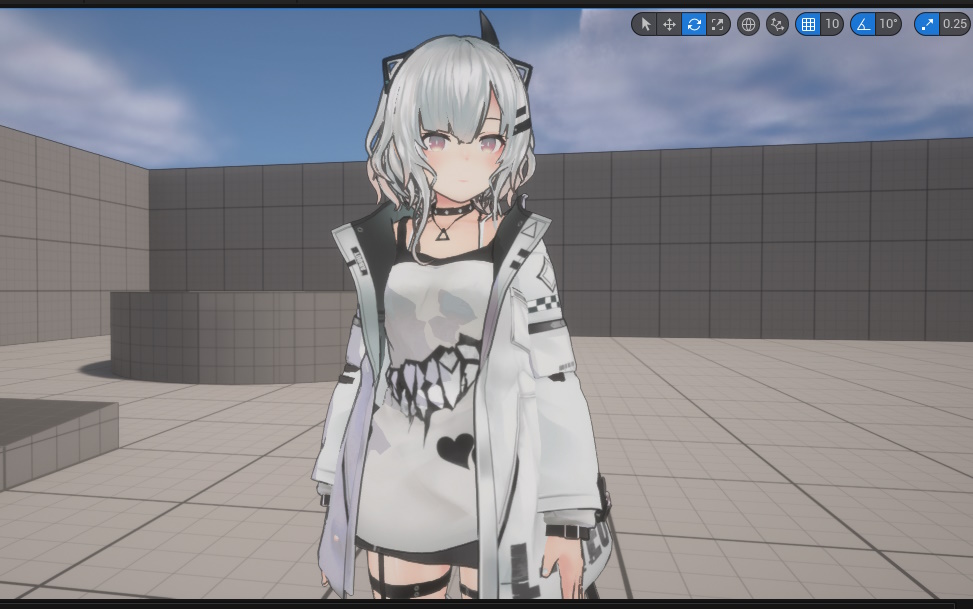
お洋服に生成したシャドウカラーテクスチャを付けてみました。
カメラを近づけるとグラデーションの崩壊がバレてしまうので遠目からです。
おわり!!!
お疲れさまでした!!!
深夜テンションの思い付きから突貫コーディングで始めましたが意外とぽいものができて且つ学びも得られたので割と満足な結果でした。というかこんな雑なことしてもそれっぽい挙動をしてくれるニューラルネットワークの賢さたるや。
他にもやりたいこと色々あるのでそっちが落ち着いたらこの手法についてもう少し研究するのも楽しそうですね。