こんにちは!!!クライアントエンジニアの小林です。
今回はDistilBERTのMaskedLMを利用して類似文字を推定してもらいます。
- 概要
- DistilBERTとは
- Tokenizerとは
- MaskedLMとは
- FineTuningとは
- 類似文字推定とは
- DistilBERTの学習済みモデルの選定
- Tokenizerの比較
- 類似文字を扱うSimilarCharacterクラス
- Tokenizerと類似文字の保存
- データセット
- DataCollator
- 学習
- 推論
- 「ぺ」の追加検証
- wikipediaとoscarデータセットを試す
- おわり!!!
- 参考
概要
DistilBERTのMaskedLMを利用して類似文字を推定します。
前半は使用しているモデルの解説や用語説明で、後半は技術検証系といった構成です。
注意点として筆者は趣味で深層学習モデルと戯れています。
それ故にひん曲がった自己解釈があるかもしれません。
なので「ほーん、ふーん」程度に見てもらえるとストレスフリーかもしれません。
DistilBERTとは
その前に自然言語とBERTの説明が必要です。
自然言語とは
我々人間が普段使っている日本語や英語などの言葉を総称して自然言語(Natural Language・NL)と呼び、自然言語で色々と処理することを自然言語処理(Natural Language Processing・NLP)と呼びます。
自然言語処理は文章分類や翻訳、単語の予想、文章生成などの多くの分野があります。
この自然言語を処理できるモデルの1つにBERTが挙げられます。
BERTとは
正式名称はBidirectional Encoder Representations from Transformers.
DeepLさんとGoogle翻訳さんに聞いてみたところ「トランスフォーマーからの双方向エンコーダ表現」とのことです。
TransformerはBERTに組み込まれている深層学習モデルの名称で、双方向は学習手法のようなものです。
Transformerは一旦置いておいて、双方向から触れていきます。
BERTが登場する以前の話になりますが、それまでの主流は双方向ではなく、単方向でした。
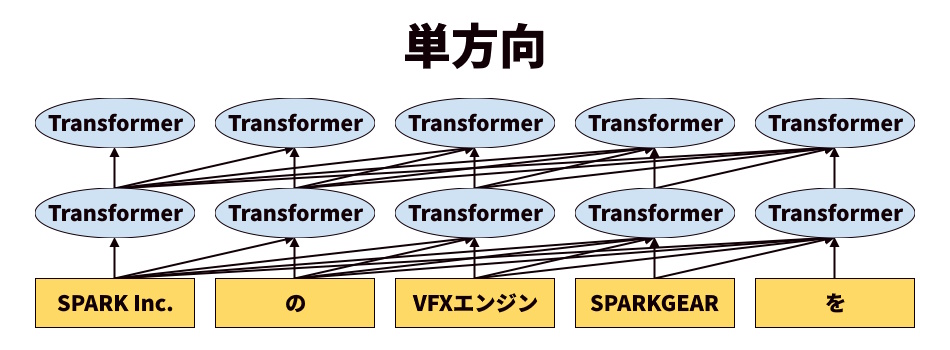
単方向というのは画像のとおり、単語の位置から前方もしくは後方にのみ、単語との関係性を学習していく手法です。
例として「SPARK Inc.」の次に来る単語はなにか、という問いに対しては「VFXエンジン」や「SPARKGEAR」などが得られます。
では、「SPARKGEAR」の後ろに来る単語はなにか、という問いに対してはどうでしょうか。
単方向ではこの問いに対して正しい回答ができません。
それも当然です。学習していないのですから。
では次に双方向の画像を見てみます。
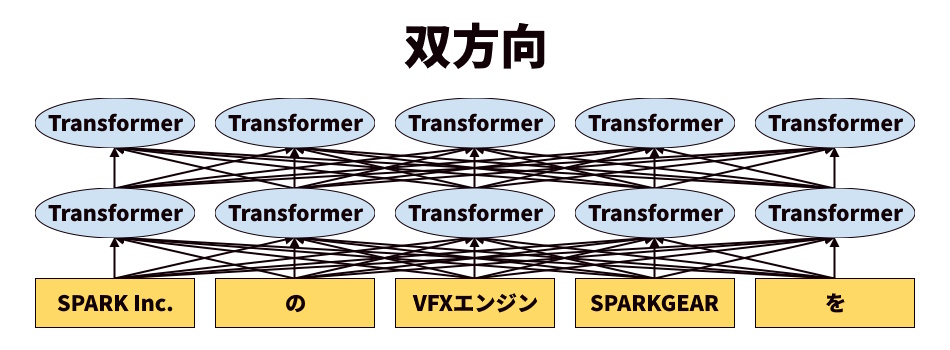
単方向とは異なり、単語の位置から前方と後方の両方に対して、単語との関係性を学習しています。
つまりは先ほど答えられなかった「SPARKGEAR」の後ろに来る単語はなにか、という問いに対して「SPARK Inc.」や「VFXエンジン」などの結果を得ることができます。
改めてですが、双方向では前後の単語の関係性を考慮して学習をしています。
これはつまり文法を学習しているといえます。
この文法理解が単方向と双方向の大きな違いです。
身近な例でいうと、
英文を読む際に、単語だけを理解している人と、単語と文法の両方を理解している人では、結果が異なりますよね。
それと似たような感じです。
このようにBERTは双方向な学習により、文法を理解できる賢い自然言語処理モデルになりました。
双方向の賢さについて説明をしましたが、割とシンプルな考え方です。
そのため単方向が主流の頃から双方向で頑張ろうという試み自体はおそらくあったはずです。
しかしながらそれを現実的なコストで落とし込めるアルゴリズムやモデルが存在しなかったため、簡易版の単方向が主流になっていました。
Transformerが現れるまでは。
Transformerとは
『Attention Is All You Need』という論文で発表された深層学習モデルです。
えー、以上です。
というのも、このTransformerモデルですが、すごすぎるんです。
単方向、双方向のように簡単に触れられる内容ではないのです。
重みというそれっぽい要素を説明してしまえば割といけそうな雰囲気はあるのですが、
これ以上の説明をするのが面倒で触れたくないなぁといった筆者の事情です。
ではなぜ触れたのかというと、このTransformerモデル、汎用性がとても高いです。
その活動領域は自然言語処理に留まらず、画像分類や生成、音声認識や合成など、ほぼすべての分野において利用されるほどです。
当初は自然言語界隈にブレイクスルーを起こしたと言われていましたが、
最早界隈を越えて人類史における重要な論文の1つではないかと筆者は思うほどです。
この論文が存在しなければ、Stable DiffusionやChatGPTのような誰もが触れる高性能なモデルの登場が数年遅れてましたからね。
つまりTransformerモデルはすごいのです。
という事実だけは伝えたかったのです。
DistilBERTとは(おかえり)
自然言語処理はBERT、というよりTransformerの登場により飛躍的に精度が向上しました。
しかしながらそんなTransformerにも問題点があります。
それはパラメータ数が多いことです。
従来モデルであるGPTのパラメータ数が約1億に対して、BERTのパラメータ数はその3倍である約3億です。
Transformerにより双方向という学習手法が確立した事実を考慮すれば妥当なコスト増加ではあるのですが、
BERTの運用事情によりこのコスト増加は無視できないものになってしまいました。
BERTの説明でも述べたとおり単語と文法を学んでいます。
逆にいうとそれしか学んでいません。
厳密にはもう1要素学んでいますが省略します。
自然言語処理には文章分類や感情分析、対話など多くの分野が存在します。
それら無数の分野に対して単語と文法の標準装備で立ち向かうのは無謀、というか無理です。
そのため利用用途に合った追加の学習や調整をする必要があります。
文章分類ならそれが文章なのか会話なのかを紐づけしたテキストデータを学習させたり、
感情分析であればテキストに含まれる感情を紐づけしたものを学習させたりです。
追加学習や調整というフローは、実質的にモデル開発期間です。
そのためコスト増加が無視できない問題になり、軽量化や最適化が課題になりました。
そこで登場したのがBERTの軽量化と最適化に成功したDistilBERTという自然言語処理モデルです。
BERTとの主な違いは学習方法にあります。
BERTがテキストを元に0から学習をするのに対して、
DistilBERTはBERTを元に、BERTの入力から出力に至るまでの過程や結果を模倣するような形で学習を進めます。
模倣、つまりは真似をしているだけなのでBERTほど層を深くせずとも結果を近づけることができます。
結果的にBERTの精度の95%以上維持しつつ、パラメータ数を40%削減、学習や推論速度を60%高速化することに成功しています。
一応現状においてBERTとDistilBERTを使用する境界線が、
個人開発や精度よりも速度を重視する場合はDistilBERTを選び、
精度を重視する場合や速度をマシンパワーで強引に解決できる環境がある場合はBERT(今だとGPTですね)が選ばれる傾向らしいです。
余談ですがChatGPTで使用されているGPT-3のパラメータ数は約1750億です。
GPT-4は安全性云々でパラメータ数は非公開ですが、まぁこれ以上という予想は容易にできますね。
たった1、2年という短い期間で随分と環境変わりましたね。
Tokenizerとは
Tokenizerは自然言語処理を行うデータに対するプリプロセス、ポストプロセスの役割を担っています。
単・双方向の説明をした際に以下のテキストを例として用いました。
「SPARK Inc.のVFXエンジンSPARKGEARを」
このテキストを自然言語処理ができる形に変換してみます。
まずは単・双方向の説明画像のようにテキストを単語や文字に分割します。
分割作業は形態素解析という手法で行われ、その手法は形態素解析ツールによって若干の差はありますが、基本的には名詞や動詞の○○詞を区切りに分割されます。
形態素解析自体は機械翻訳時代から確立されている馴染み深い方法ですね。
最後に分割した単語や文字を数値に置換します。
この数値をトークンと呼び、形態素解析→トークン置換の一連の作業をトークン化やエンコードと呼びます。
トークンから単語や文字に復元、テキストに復元する作業はデコードと呼びます。
試しに例文をTokenizerでエンコードしてみます。
1列目がトークンで、2列目がそれに紐付けされる単語や文字です。
| 1813 | 4685 | 7900 | 33 | 5 | 516 | 10348 | 10503 | 2138 | 1813 | 4685 | 2582 | 240 | 13 |
| sp | ark | inc | . | の | v | f | x | エンジン | sp | ark | ge | ar | を |
単・双方向に用いた画像は説明ように筆者が偽分割をしていましたが、実際に自然言語処理で扱われるデータは表のようにかなり細分化されます。
Tokenizerはこんな感じで入出力データを処理していました。
MaskedLMとは
BERTの学習方法の1つです。
Tokenizerによりトークン化されたトークンをランダムに選出し、マスクトークとよばれる特殊なトークンに変換します。マスクトークンは文字列では[MASK]と表記されることが多いです。
BERTはマスクトークンから元のトークンを推定し、その成否によって損失が計算され学習が進められます。損失計算の詳細には触れませんが、元のトークンを推定する際に複数の回答候補があるのでそれを確立するための工夫など結構面白いことをしています。
FineTuningとは
DistilBERTで触れたタスクに合わせた追加学習の手法がFineTuningです。
FineTuningの定義付けとしては学習済みモデルを元に追加の出力層や重みの部分的初期化や固定化などがあるのですが、そんな細かいことは気にせずに調整方法の1つとしての認識ぐらいでいいと思います。
類似文字推定とは
類似文字推定を説明する前に、類似文字という概念を説明します。
皆さんは以下の画像に含まれる2つの文章を読めるでしょうか。

正解はこちらです。
「一番(いちばん)困(こま)るんですけどー(長音符)」
「能力者(のうりょくしゃ)はカッコ(かっこ)いい」
日本語を嗜んでいる方であれば難なく読める内容かと思います。
読める内容ではあるのですが、これ、地味に凄いことなんです。
何故ならそれぞれの文中には、ほぼ見た目が同じ文字が存在します。
我々人間はそれを読む際に無意識に前後の文字列や文法などの情報を元に、そこに当てはまる文字をポンっと予想したり記憶から引っこ抜いているのです。
2つの文章には「一」と「ー」、「力」と「カ」といったように見た目が同じ文字が含まれていました。
これらが類似文字です。
以上の類似文字の説明が終わった時点で、類似文字推定の概要は容易に想像付くでしょうが一応しますね。
例として「能力者」の類似文字推定を行うのであれば、「能○者」の○が漢字の力(ちから)なのか、カタカナのカ(か)なのかを推定するということを指します。
これらを踏まえて先ほどの2つの文章をMaskedLMな記述にするとこうですね。
「[MASK]番困るんですけど[MASK]」
「能[MASK]者は[MASK]ッコいい」
このような類似文字を正しく穴埋めできるモデルにチューニングしていきます。
前説が長かった。。。
我ながら色んなモデルやら技術と戯れているのだなと再認識し、少し誇らしくなりました。
えっへん。
DistilBERTの学習済みモデルの選定
FineTuningを行うベースとなるモデルを選んでいきます。
DistilBERTの学習済みモデルはいくつか公開されていますが、今回は2つの中から選びたいと思います。
1つはバンダイナムコ研究所さんが公開しているモデルです。
wikipediaを元に学習したモデルのため、当然ながらデータ量が膨大で精度もそれなりです。
もう1つはなんと2023年3月と結構最近に、LINE株式会社さんが新たな学習済みモデルを公開しておりました。
ChatGPT界隈が盛り上がっている中での公開って宣伝効果的にどうなんだろうとも思いましたが、この調子だとChatGPTが主流になり、軽量化と独自モデルの文化は暫く廃れそうな予感もするので適当な時期なんでしょうか。
そしてLINE株式会社さんが公開したモデルですがなんと、独自のテキストデータを元に学習しているそうです。
当然ながら独自のテキストデータを持っているので、教師モデルも自社で構築したものを使用しています。
SNSの開発・運営経験がある会社さんのテキストデータとか実用性◎なのでは?!?!と筆者はかなり期待しております。
実際、公式がLINE DistilBERTを紹介しているページ内ではバンナム研究所モデルよりも高精度であることが証明されています。
とはいえ今回は類似文字推定です。
もしかしたら、もしかするかもしれないので一応比較検証しておきます。
以下は類似文字推定の精度結果です。
精度算出コードは後半お見せするので今はスルーでお願いします。
| モデル | 類似文字総数/推定成功数/推定失敗数 |
|---|---|
| bandainamco-mirai/distilbert-base-japanese | 2,939/2,665/274 |
| line-corporation/line-distilbert-base-japanese | 2,939/2,825/114 |
おぉ。
2倍も違います。
念のため1エポックだけFineTuningしたモデルでも計測してみます。
FineTuningについても同様で後半に記述しますので、どうやっているかは一旦スルーで結果にだけ注目頂ければです。
| モデル | 類似文字総数/推定成功数/推定失敗数 |
|---|---|
| bandainamco-mirai/distilbert-base-japanese | 2,939/2,842/97 |
| line-corporation/line-distilbert-base-japanese | 2,939/2,899/40 |
FineTuning後も結果が逆転したり狭まったりすることもないみたいなので、素直にLINE DistilBERTを選択で良いでしょう。
厳密にはFineTuning後の推定成功率の上昇幅はバンナム研究所さんが勝っていますが、そもそもの失敗数が多いことが要因なため、考慮する必要はないでしょう。
Tokenizerの比較
BNE DistilBERTとLINE DistilBERTでは使用しているTokenizerが異なります。
BNE DistilBERTは東北大学さんが公開しているTokenizerを使用しているのに対して、LINE DistilBERTはLINE独自のTokenizerです。
どの程度の差分があるのか気になるので覗いてみます。
語彙リストの差分
まずは語彙リストの差分をざっくり見てみます。
先頭と末尾をそれぞれ20単語抽出してみました。

先頭から差分があるので思ったよりも独自感強めですね。
サブトークンの分割をハッシュではなくブロック要素にしているのはなにか理由があるのでしょうか。
筆者には意図を汲み取れなかったです。
末尾に関しては明らかに珍しそうな漢字が含まれています。
語彙リストに含まれる文字の差分
思った以上に差分がありました。
もう少し興味が出てきたので、語彙リストに含まれる重複しない文字と文字数を確認してみます。
文字数が多いのでvscodeのプレビュー制限に引っかかってますが、全部を見たい訳ではないので気にしないで進めます。
左がBNE(東北大学)、右がLINEです。

一目瞭然ですね。
数値で比べると東北大学さんが3,556文字に対して、LINEが21,774文字です。
特殊文字もカウントしているので厳密な数値ではありませんが、それを考慮したとしても圧倒的な差です。
これだけ対応文字が幅広いと不明トークンになる可能性が大幅に減りそうですね。
LINE DistilBERTの高精度は対応文字数の多さも関係しているのでしょうか。
それにしてもこの対応数はすごいですね。
結果が出力された時、思わず声出ちゃいました。
ひらがなの「ぺ」の不思議
Tokenizerの差分を色々と確認している際に不思議なことが起こりました。
ひらがなの「ぺ」をトークン化すると10234と12267のIDが振り分けられたのです。

筆者はてっきり1単語につき1つのトークンだと思っていたので驚きました。
さらに不思議なことに10234をデコードしても空白文字が出力され、12267をデコードすると「ぺ」が出力されるという。
text_list = [
" ぺ た ぺ た。 ぺ た ぺ た。いくらか冷静になると、",
"あっ( ぺ こっ)",
" ぺ こりと、丁寧に頭を下げる。",
"うっし、かん ぺ きぃっ",
"まぁ、実際言い出しっ ぺ だからな",
]
for text in text_list:
for id in tokenizer.encode(text, add_special_tokens=False):
if len(decode:=tokenizer.decode(id)) >= 0:
print(id, decode)
print("================")

この結果だけ見ると推論時においては10234は不必要だと思うのですが、学習時に必要としているトークンなんでしょうか。
不思議は解決していませんが、とりあえず気付けてよかったです。
類似文字推定の設計では1単語1トークンで紐付けていたので、気づかなかったらバグったまま動かしているところでした。
検証用のコード
LINE DistilBERTが公開されてから2週間後ぐらいのリビジョンを指定しています。
もしかしたら最新リビジョンだと結果は変わるかも?しれないです。
import pandas as pd import itertools from transformers import AutoTokenizer, logging if __name__ == "__main__": # エラー未満のログを非表示 logging.set_verbosity_error() cache_dir = r"cache" bne_tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking", cache_dir=cache_dir) # warning: # The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization. # The tokenizer class you load from this checkpoint is 'BertJapaneseTokenizer'. # The class this function is called from is 'DistilBertJapaneseTokenizer'. line_tokenizer = AutoTokenizer.from_pretrained("line-corporation/line-distilbert-base-japanese", cache_dir=cache_dir, trust_remote_code=True, revision="bcbdf6df31d2ef58bb6288f7aa4906fc688969a5") bne_vocab = {val: key for key, val in bne_tokenizer.get_vocab().items()} bne_vocab_num = len(bne_vocab) assert len(bne_vocab) == len(bne_tokenizer.get_vocab()), "duplicate val." line_vocab = {val: key for key, val in line_tokenizer.get_vocab().items()} line_vocab_num = len(line_vocab) assert len(line_vocab) == len(line_tokenizer.get_vocab()), "duplicate val." vocab_table = [[bne_vocab[id] if id < bne_vocab_num else None, line_vocab[id] if id < line_vocab_num else None] for id in range(max(bne_vocab_num, line_vocab_num))] df = pd.DataFrame(vocab_table, columns=["BNE", "LINE"]) #print(df.head(20)) #print(df.tail(20)) bne_vocab2char = set(list(itertools.chain.from_iterable([[char for char in vocab] for vocab in bne_vocab.values()]))) line_vocab2char = set(list(itertools.chain.from_iterable([[char for char in vocab] for vocab in line_vocab.values()]))) #print(len(bne_vocab2char), len(line_vocab2char)) #print(bne_vocab2char) #print(line_vocab2char)
類似文字を扱うSimilarCharacterクラス
類似文字の一覧とそれに対応したトークンを保持させるSimilarCharacterデータクラスを作成します。
初回のみ類似文字の生データとTokenizerを元に初期化を行います。
2回目以降はjson形式で保存された情報を元にSimilarクラスをセットアップしてTokenizerの依存度を減らすことにします。
毎回Tokenizerからトークン抽出をするのは無駄なコストですからね。
例のひらがな「ぺ」は一旦custom_encodeで空白トークンを取り除くことにします。
Similarクラスの他に、全角から半角と半角から全角のマップ、hugging faceのログレベルのデフォルト値を変更する処理も一緒に置いておきます。
# common.py import itertools from dataclasses import dataclass from typing import Union, Any from copy import deepcopy from pathlib import Path import json from transformers import PreTrainedTokenizer, logging __all__ = [ "FULL2HALF", "HALF2FULL", "Similar", ] # エラー未満のログを非表示 logging.set_verbosity_error() # 全角から半角 FULL2HALF = {chr(0xFF01 + i): chr(0x0021 + i) for i in range(94)} # 半角から全角 HALF2FULL = {chr(0x0021 + i): chr(0xFF01 + i) for i in range(94)} @dataclass class Similar: """類似文字情報 """ similar_list:list[list[str]] converted_similar_list:list[list[str]] similar:str similar_tokens:dict[str, int] similar_label:dict[str, dict[int, str]] similar_pattern:str converted_similar:str converted_similar_tokens:dict[str, int] converted_similar_label:dict[str, dict[int, str]] converted_similar_pattern:str def __init__( self, data_or_dir:Union[str, Path, list[list[str]]], tokenizer:Union[PreTrainedTokenizer, None]=None, ): """コンストラクタ Args: data_or_dir (Union[str, Path, list[list[str]]]): 類似文字データのパスか、生データを指定 tokenizer (Union[PreTrainedTokenizer, None], optional): 生データを指定した場合はTokenizerも必要. Defaults to None. """ if isinstance(data_or_dir, str): self.init_from_dir(Path(data_or_dir)) elif isinstance(data_or_dir, Path): self.init_from_dir(data_or_dir) elif isinstance(data_or_dir, list) and isinstance(tokenizer, PreTrainedTokenizer): self.init_from_data(data_or_dir, tokenizer) else: assert False, "'data_or_dir' requires str or list and PreTrainedTokenizer." def init_from_dir(self, similar_dir:Path) -> None: """出力済みの類似文字データから初期化 Args: similar_dir (Path): 類似文字データが存在するディレクトリ """ with open(str(similar_dir / "similar.json"), mode="r", encoding="utf-8") as f: self.__dict__ = json.load(f) self.similar_label = { similar: {int(token): char for token, char in vals.items()} for similar, vals in self.similar_label.items() } self.converted_similar_label = { similar: {int(token): char for token, char in vals.items()} for similar, vals in self.converted_similar_label.items() } def init_from_data(self, similar_list:list[list[str]], tokenizer:PreTrainedTokenizer) -> None: """生データから類似文字の初期化 Args: similar_list (list[list[str]]): 類似文字 tokenizer (PreTrainedTokenizer): Tokenizer """ full2half = str.maketrans(FULL2HALF) self.similar_list = deepcopy(similar_list) self.converted_similar_list = [[char.translate(full2half) for char in similar] for similar in similar_list] def custom_encode(char:str, tokenizer:PreTrainedTokenizer) -> int: tokens = tokenizer.encode(char, add_special_tokens=False) if len(tokens) == 1: return tokens[0] tokens = [token for token in tokens if len(tokenizer.decode(token, skip_special_tokens=True)) > 0] if len(tokens) == 1: return tokens[0] assert False, "???????????" self.similar = "".join(self.to_flatten(self.similar_list)) self.similar_tokens = {char: custom_encode(char, tokenizer) for char in self.similar} self.similar_label = {chars[0]: {self.similar_tokens[char]: char for char in chars} for chars in self.similar_list} self.similar_pattern = f"([{self.similar}])" self.converted_similar = self.similar.translate(full2half) self.converted_similar_tokens = {char: custom_encode(char, tokenizer) for char in self.converted_similar} self.converted_similar_label = {chars[0]: {self.converted_similar_tokens[char]: char for char in chars} for chars in self.converted_similar_list} self.converted_similar_pattern = f"([{self.converted_similar}])" def to_flatten(self, x:list[list[Any]]) -> list[Any]: """2d array to 1d array Args: x (list[list[Any]]): 2d array Returns: list[Any]: 1d aray """ return list(itertools.chain.from_iterable(x)) def save(self, output_dir:Union[Path, str]) -> None: """類似文字情報をjson形式で保存 Args: output_dir (Union[Path, str]): 保存先のディレクトリ """ if isinstance(output_dir, str): output_dir:Path = Path(output_dir) elif not isinstance(output_dir, Path): assert False, "'output_dir' requires Path or str." with open(str(output_dir / "similar.json"), mode="w", encoding="utf-8") as f: json.dump(self.__dict__, f, indent=2, ensure_ascii=False)
Tokenizerと類似文字の保存
Tokenizerと類似文字は頻繁に使用するので任意のフォルダに保存しておきます。
類似文字はADVでよく使われるフォント、モトヤLマルベリ3等幅基準で選んでいます。
この他にMSゴシックや源ノ角ゴシックなども使うため、出力ディレクトリの名前にはフォント名を指定しています。
# create_tokenizer_and_similar.py from pathlib import Path from transformers import AutoTokenizer from common import * def my_app( output_dir:str, similar_list:list[list[str]], cache_dir:str=r"cache", revision:str="bcbdf6df31d2ef58bb6288f7aa4906fc688969a5", ): # to Path output_dir:Path = Path(output_dir) # warning: # The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization. # The tokenizer class you load from this checkpoint is 'BertJapaneseTokenizer'. # The class this function is called from is 'DistilBertJapaneseTokenizer'. tokenizer = AutoTokenizer.from_pretrained("line-corporation/line-distilbert-base-japanese", cache_dir=cache_dir, trust_remote_code=True, revision=revision) tokenizer.save_pretrained(str(output_dir / "tokenizer")) similar = SimilarCharacter(similar_list, tokenizer) similar.save(output_dir) if __name__ == "__main__": output_dir = r"mtlmr3m" similar_list = [ ["ロ", "口"], ["ー", "一"], ["カ", "力"], ["エ", "工"], ["I", "l"], ["へ", "ヘ"], ["べ", "ベ"], ["ぺ", "ペ"], ["0", "O"], ["タ", "夕"], ["ニ", "二"], ] my_app(output_dir, similar_list)

データセット
使用するデータセットは、wikipediaデータベースを元に作成されたGEM/wiki_linguaと、amazonのレビューを元に作成されたtyqiangz/multilingual-sentimentsの2つです。
最終的にはwikipediaデータベースを使用する予定ですが、動作確認的な意味で比較的軽量なデータセットを選びました。
類似文字のみをマスク化するための文章化
MaskedLMの学習方法は文中の単語をランダムにマスク化、それを予想することで進められます。
類似文字推定においてはランダムだと困るため類似文字だけをマスク化します。
類似文字だけをマスク化するために文中に類似文字が含まれる場合にはその前後に半角スペースを挿入し、形態素解析がそれを単語として認識できないようにします。
before: したのが視力検査の after : したのが視 力 検査の
頻出の偏りを軽減
データセットの分割方法も改良します。
デフォルトの分割方法ではseed値によるシャッフル後にスライスを行いますが、これではtrainとvalidの片方にのみ頻出する類似文字やそれに付随する単語が発生してしまいます。
これを抑制するために、使用するデータセットから類似文字ごとにファイルを作成し、そこに文章を保存します。
最後にデータセットを作成する際に、ファイルごとにtrainとvalidに分割することで頻出の偏りを解決します。
付随する単語の偏り問題は未解決ですが、これを考慮すると細分化がえらいことになるため、精度の高止まりが起きるまでは無視して進めることとします。
GEM/wiki_lingua
# convert_wiki_lingua.py import re from pathlib import Path from tqdm import tqdm from io import TextIOWrapper from pprint import pprint from datasets import load_dataset from common import * def my_app( root_dir:str, dataset_name:str="wiki_lingua", cache_dir:str=r"cache", ): # to Path root_dir:Path = Path(root_dir) # データセットの出力先を作成 output_dir = root_dir / dataset_name output_dir.mkdir(parents=True, exist_ok=True) dataset = load_dataset("GEM/wiki_lingua", "ja", cache_dir=cache_dir) # 変換マップの作成 full2half = str.maketrans(FULL2HALF) similar = SimilarCharacter(root_dir) # trainとvalidで出現数の偏りを減らすため、類似文字ごとにテキストを保存 similar_tokens:dict[str, TextIOWrapper] = { char: open(f"{str(output_dir)}\\{dataset_name}_{token}.txt", mode="w", encoding="utf-8") for char, token in similar.converted_similar_tokens.items() } # サンプル数 sample_count:dict[str, int] = {char: 0 for char in similar.converted_similar} # すべてのサンプルに含まれる類似文字数 total_similar_count:dict[str, int] = sample_count.copy() for stage in (stage_pbar:=tqdm(list(dataset.keys()))): stage_pbar.set_description(stage) for source in tqdm(dataset[stage]["source"], total=len(dataset[stage]["source"]), leave=False): # 全角to半角 source:str = source.translate(full2half) # 改行文字に置換 source = re.sub("。 |。 ", "。\n", source) # 改行 text_list:list[str] = source.splitlines() for text in text_list: # テキストに含まれる類似文字数 similar_count = {char: count for char in similar.converted_similar if (count:=text.count(char)) > 0} if len(similar_count) == 0: continue # サンプル数が少ない類似文字順に書き込み先を探す for key, val in sample_count.items(): if key in similar_count.keys(): text = re.sub(similar.converted_similar_pattern, " \\1 ", text) similar_tokens[key].write(text + "\n") sample_count[key] += 1 sample_count = dict(sorted(sample_count.items(), key=lambda x:x[1])) break # 類似文字総数の更新 for key, val in similar_count.items(): total_similar_count[key] += val for key, val in similar_tokens.items(): val.close() sample_count = dict(sorted(sample_count.items(), key=lambda x:x[1])) total_similar_count = dict(sorted(total_similar_count.items(), key=lambda x:x[1])) pprint(sample_count, sort_dicts=False) pprint(total_similar_count, sort_dicts=False) if __name__ == "__main__": root_dir = r"mtlmr3m" my_app(root_dir)

tyqiangz/multilingual-sentiments
# convert_multilingual_sentiments.py import re from pathlib import Path from tqdm import tqdm from io import TextIOWrapper from pprint import pprint from datasets import load_dataset from common import * def my_app( root_dir:str, dataset_name:str="multilingual_sentiments", cache_dir:str=r"cache", ): # to Path root_dir:Path = Path(root_dir) # データセットの出力先を作成 output_dir = root_dir / dataset_name output_dir.mkdir(parents=True, exist_ok=True) dataset = load_dataset("tyqiangz/multilingual-sentiments", "japanese", cache_dir=cache_dir) # 変換マップの作成 full2half = str.maketrans(FULL2HALF) similar = SimilarCharacter(root_dir) # trainとvalidで出現数の偏りを減らすため、類似文字ごとにテキストを保存 similar_tokens:dict[str, TextIOWrapper] = { char: open(f"{str(output_dir)}\\{dataset_name}_{token}.txt", mode="w", encoding="utf-8") for char, token in similar.converted_similar_tokens.items() } # サンプル数 sample_count:dict[str, int] = {char: 0 for char in similar.converted_similar} # すべてのサンプルに含まれる類似文字数 total_similar_count:dict[str, int] = sample_count.copy() for stage in (stage_pbar:=tqdm(list(dataset.keys()))): stage_pbar.set_description(stage) for source in tqdm(dataset[stage]["text"], total=len(dataset[stage]["text"]), leave=False): # 全角to半角 source:str = source.translate(full2half) # 改行文字に置換 source = re.sub("。 |。 ", "。\n", source) # 改行 text_list:list[str] = source.splitlines() for text in text_list: # テキストに含まれる類似文字数 similar_count = {char: count for char in similar.converted_similar if (count:=text.count(char)) > 0} if len(similar_count) == 0: continue # サンプル数が少ない類似文字順に書き込み先を探す for key, val in sample_count.items(): if key in similar_count.keys(): text = re.sub(similar.converted_similar_pattern, " \\1 ", text) similar_tokens[key].write(text + "\n") sample_count[key] += 1 sample_count = dict(sorted(sample_count.items(), key=lambda x:x[1])) break # 類似文字総数の更新 for key, val in similar_count.items(): total_similar_count[key] += val for key, val in similar_tokens.items(): val.close() sample_count = dict(sorted(sample_count.items(), key=lambda x:x[1])) total_similar_count = dict(sorted(total_similar_count.items(), key=lambda x:x[1])) pprint(sample_count, sort_dicts=False) pprint(total_similar_count, sort_dicts=False) if __name__ == "__main__": root_dir = r"mtlmr3m" my_app(root_dir)

データセットの作成
# create_dataset.py from pathlib import Path import random from tqdm import tqdm def my_app( output_dir:str, dataset_dir:str, ratio:float=0.7, ): # to Path output_dir:Path = Path(output_dir) dataset_dir:Path = Path(dataset_dir) output_dir.mkdir(parents=True, exist_ok=True) dataset_paths = [path for path in dataset_dir.glob("*.txt")] train_list:list[str] = [] valid_list:list[str] = [] for dataset_path in tqdm(dataset_paths): with open(str(dataset_path), mode="r", encoding="utf-8") as f: text_list = f.readlines() random.shuffle(text_list) index = int(len(text_list)*ratio) train_list.extend(text_list[:index]) valid_list.extend(text_list[index:]) with open(str(output_dir / f"{dataset_dir.name}_train.txt"), mode="w", encoding="utf-8") as f: f.writelines(train_list) with open(str(output_dir / f"{dataset_dir.name}_valid.txt"), mode="w", encoding="utf-8") as f: f.writelines(valid_list) if __name__ == "__main__": my_app( r"mtlmr3m\datasets", r"mtlmr3m\multilingual_sentiments", )

DataCollator
MaskedLMで使用されるDataCollatorはランダムなトークンを任意の確率でマスク化していますが、類似文字推定ではマスク化するべきトークンが定まっているためランダム処理を封印します。
また、マスク化の確率もよく使われる15%や40%ではなく、100%に変更して確実に類似文字をマスク化しています。確率化しない理由としては文中に含まれる類似文字がそもそも少なく確率化してしまうとデータ不足に陥りがちなためです。
# data_collator.py from dataclasses import dataclass from typing import Any, Tuple, List, Dict, Union, Mapping import torch from transformers.data.data_collator import ( PreTrainedTokenizerBase, DataCollatorMixin, _torch_collate_batch, ) __all__ = [ "DataCollatorForLanguageModeling", ] @dataclass class DataCollatorForLanguageModeling(DataCollatorMixin): tokenizer: PreTrainedTokenizerBase return_tensors: str = "pt" mask_ids: List[int] = None all_special_ids: List[int] = None def __post_init__(self): self.mask_ids = torch.tensor(self.mask_ids) self.all_special_ids = torch.tensor(self.tokenizer.all_special_ids) def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]: # Handle dict or lists with proper padding and conversion to tensor. if isinstance(examples[0], Mapping): batch = self.tokenizer.pad(examples, return_tensors="pt") else: batch = { "input_ids": _torch_collate_batch(examples, self.tokenizer) } batch["input_ids"], batch["labels"] = self.torch_mask_tokens(batch["input_ids"]) return batch def torch_mask_tokens(self, inputs: Any) -> Tuple[Any, Any]: """ Prepare masked tokens inputs/labels for masked language modeling. """ labels = inputs.clone() masked_indices = torch.isin(labels, self.mask_ids) labels[~masked_indices] = -100 inputs[masked_indices] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token) return inputs, labels
学習
HuggingFaceの公式ドキュメントを参考に実装しました。
流れとしてはテキストデータをバッチ化してから学習に入るようです。
バッチ化も長さを渡すだけで勝手に進めてくれます。
PyTorch Lightningに比べると随分とシンプルな構成ですね。
# train.py import os from functools import partial from pathlib import Path from datasets import load_dataset from transformers import ( AutoModelForMaskedLM, AutoTokenizer, Trainer, TrainingArguments, logging, ) from create_tokenizer_and_similar import * from data_collator import * def tokenize_function(examples, tokenizer): text = examples["text"] result = tokenizer(text, verbose=False) return result def group_texts(examples, chunk_size:int): # Concatenate all texts concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()} # Compute length of concatenated texts total_length = len(concatenated_examples[list(examples.keys())[0]]) # We drop the last chunk if it's smaller than chunk_size total_length = (total_length // chunk_size) * chunk_size # Split by chunks of max_len result = { k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)] for k, t in concatenated_examples.items() } # Create a new labels column result["labels"] = result["input_ids"].copy() return result def my_app( root_dir:str, output_dir:str, train_dataset_paths:list[str], valid_dataset_paths:list[str], chunk_size:int=512, batch_size:int=32, lr:float=1e-05, weight_decay:float=0.01, epochs:int=5, num_proc:int=8, cache_dir:str=r"cache", ): # to Path root_dir:Path = Path(root_dir) logging.set_verbosity_debug() tokenizer = AutoTokenizer.from_pretrained(str(root_dir / "tokenizer"), trust_remote_code=True) similar = Similar(root_dir) dataset = load_dataset("text", data_files={"train":train_dataset_paths, "validation":valid_dataset_paths}, cache_dir=cache_dir) tokenized_datasets = dataset.map(partial(tokenize_function, tokenizer=tokenizer), batched=True, remove_columns=["text"], num_proc=num_proc) lm_datasets = tokenized_datasets.map(partial(group_texts, chunk_size=chunk_size), batched=True, num_proc=num_proc) mask_ids = list(similar.converted_similar_tokens.values()) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mask_ids=mask_ids) model = AutoModelForMaskedLM.from_pretrained("line-corporation/line-distilbert-base-japanese", cache_dir=cache_dir) output_dir:Path = Path(output_dir) output_version = [int(dir.stem.split("_")[1]) for dir in output_dir.glob("**") if dir.name.startswith("version_")] output_version = max(output_version) + 1 if len(output_version) > 0 else 0 output_dir = output_dir / f"version_{output_version}" output_dir.mkdir(parents=True, exist_ok=True) training_args = TrainingArguments( output_dir=str(output_dir), overwrite_output_dir=True, learning_rate=lr, weight_decay=weight_decay, per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, fp16=True, save_strategy="no", optim="adamw_torch", logging_strategy="epoch", lr_scheduler_type="cosine", num_train_epochs=epochs, evaluation_strategy="epoch", seed=522, ) trainer = Trainer( model=model, args=training_args, train_dataset=lm_datasets["train"], eval_dataset=lm_datasets["validation"], data_collator=data_collator, tokenizer=tokenizer, ) trainer.train() model_dir = output_dir / "model" model_dir.mkdir(parents=True, exist_ok=True) model.save_pretrained(str(model_dir)) if __name__ == "__main__": dataset_paths = [ r"mtlmr3m\datasets\multilingual_sentiments", r"mtlmr3m\datasets\wiki_lingua", ] train_dataset_paths = [f"{dataset_path}_train.txt" for dataset_path in dataset_paths] valid_dataset_paths = [f"{dataset_path}_valid.txt" for dataset_path in dataset_paths] my_app( r"mtlmr3m", r"mtlmr3m\log_logs", train_dataset_paths, valid_dataset_paths, epochs=1, num_proc=os.cpu_count(), )
推論
類似文字推定な前処理の有効性を確かめる意味でもエポックごとに結果を確認してみます。
| epochs | 精度 (総数/正解/失敗) |
|---|---|
| 1 | 2610 / 2584 / 26 |
| 2 | 2610 / 2587 / 23 |
| 3 | 2610 / 2589 / 21 |
| 4 | 2610 / 2590 / 20 |
| 5 | 2610 / 2593 / 17 |
| 6 | 2610 / 2595 / 15 |
学習を重ねるたびに精度が向上しているのが確認できました。
ある程度進むと高止まりしている雰囲気を感じたため失敗例を確認したところ、
データセットに含まれない類似文字を含む宇単語を推定しようとしていました。
具体例を挙げると「女子力」や「七夕」などです。
これに関してはモデルは悪くないのでデータセットの見直しが必要ですね。
可能であれば軽量な2つのデータセットで終わらせたかったのですが、仕方がないので別のデータセットで再計測してみます。
類似文字推定の処理について
ADV、ノベルゲームに特化した文字認識のポストプロセスに使用するという運用上、対象のテキストが少し特殊になっています。
具体例では、台詞の前に名前が表示されていたり、セリフが鉤括弧で囲われていたり、空白表現に長音符や環境依存文字を使っていたりなどです。
最後の空白表現は作品ごとに異なるので厄介なのですが筆者は長音符で表記を統一しています。
長音符と環境依存文字の分類が難しすぎたためです。
記号の他にも架空の単語、地名や人名、固有名詞などもありますね。
これらの特殊性を考慮した上で以下のような処理フローとなっています。
- テキストの各位置が類似文字なら印を付ける
- 長音符が2文字以上連続した場合、その長音符に付けられた印を排除(システム辞書)
- テキストにユーザーが用意した辞書の単語が含まれる場合は置換
置換した文字列に類似文字の印が付けられている場合は印を排除(ユーザー辞書) - システム、ユーザー辞書適用後に印が残っている場合は、MaskedLMによる類似文字推定を実行
長音符は空白表現「ーーー季節は冬。」や口語「いいわけあるかーーーーー!」に多用されている割にデータセットにあまり含まれていないため置換での対応としました。
ユーザー辞書は主に人名や作品内でしか登場しない架空の名称などに対応するためのものです。
推論用のコード
# test.py from pathlib import Path import torch from transformers import ( DistilBertForMaskedLM, AutoTokenizer, ) from common import * def apply_dictionary( text:str, marks:list[int], dictionary:dict[str, str], ) -> str: """辞書を適用 文字列を置換した位置はmarksを0に書き換えている Args: text (str): _description_ marks (list[int]): _description_ dictionary (dict[str, str]): _description_ Returns: str: _description_ """ # 検索単語と置換単語 for fword, rword in dictionary.items(): # start = 0 # while (start:=text.find(fword, start)) != -1: # 終点位置 end = start + len(fword) # 辞書ワードによる置換 text = text[:start] + rword + text[end:] # 置換箇所は[MASK]トークンを挿入不可に for index in range(start, end): marks[index] = 0 # 検索開始位置を終点から start = end return text def load_text( path:Path, test_mode:bool=True, ) -> list[str]: """テキストファイルの読込 Args: path (Path): _description_ test_mode (bool, optional): 鍵括弧内のテキストを分割するか. Defaults to True. Returns: list[str]: _description_ """ with open(str(path), mode="r", encoding="utf-8") as f: text_list = f.read().split("\n") output_list:list[str] = [] for text in text_list: if test_mode: if ((start:=text.find("「")) != -1) and ((end:=text.rfind("」")) != -1): text = text[start+1:end] if text[-1] != "。": text += "。" output_list.append(text) else: output_list.append(text) else: output_list.append(text) return output_list def my_app( root_dir:str, model_dir:str, system_dictionary:dict[str, str], user_dictionary_list:list[dict[str, str]], cache_dir:str=r"cache", ): # to Path root_dir = Path(root_dir) model_dir = Path(model_dir) assert len(text_path_list) == len(user_dictionary_list), "not match length." tokenizer = AutoTokenizer.from_pretrained(str(root_dir / "tokenizer"), trust_remote_code=True, cache_dir=cache_dir) similar = Similar(root_dir) model = DistilBertForMaskedLM.from_pretrained(str(model_dir / "model"), cache_dir=cache_dir) model.cuda() model.eval() # OCR用の変換処理 to_similar = str.maketrans({ char: similar[0] for similar in similar.similar_list for char in similar if char != similar[0] }) similar_label = similar.similar_label total, success, fail = 0, 0, 0 for text_path, user_dictionary in zip(text_path_list, user_dictionary_list): # 正解データ label_list:list[str] = load_text(text_path) # 正解データからOCRからの入力データを作成 text_list:list[str] = [label.translate(to_similar) for label in label_list] print(text_path) for idx, (label, text) in enumerate(zip(label_list, text_list)): # 類似文字に印をつける masked_mark = [int(char in similar_label.keys()) for char in text] # テキストに類似文字が含まれない if sum(masked_mark) == 0: continue # システム辞書とユーザー辞書を適用 text = apply_dictionary(text, masked_mark, system_dictionary) text = apply_dictionary(text, masked_mark, user_dictionary) # 辞書適用により類似文字が解決した場合 if sum(masked_mark) == 0: continue # count total += sum(masked_mark) success += sum(masked_mark) # 類似文字をマスクトークンに置換[MASK]に置換 masked_text = "".join([tokenizer.mask_token if bool(mask) else char for char, mask in zip(text, masked_mark)]) with torch.no_grad(): # create inputs. inputs = tokenizer.encode(masked_text, return_tensors="pt") inputs = inputs.cuda() # Masked ML token_logits = model(inputs).logits # マスクトークン位置だけを抽出してスコアソート mask_token_index = torch.where(inputs == tokenizer.mask_token_id)[1] mask_token_logits = token_logits[:, mask_token_index, :] top_tokens = torch.topk(mask_token_logits, mask_token_logits.shape[2], dim=-1).indices[0].tolist() for tokens in top_tokens: key = text[(idx:=masked_text.find(tokenizer.mask_token)):idx+1] for token in tokens: if token in similar_label[key].keys(): masked_text = masked_text.replace(tokenizer.mask_token, similar_label[key][token], 1) break # 成否判定 is_ok = True result_text = "" for idx, (label, char) in enumerate(zip(label, masked_text)): if label == char: result_text += char else: result_text += f"[{char}]" is_ok = False success -= 1 fail += 1 if is_ok: #print(f"ok: {result_text}") pass else: print(f"ng: {idx} | {result_text}") pass print("") print(total, success, fail) if __name__ == "__main__": text_path_list = [ r"..\resources\data\test\text.txt", r"..\resources\data\test2\text.txt", r"..\resources\data\test3\text.txt", r"..\resources\data\test4\text.txt", r"..\resources\data\test5\text.txt", r"..\resources\data\test6\text.txt", r"..\resources\data\test7\text.txt", r"..\resources\data\test8\text.txt", r"..\resources\data\test9\text.txt", ] # システム辞書 system_dictionary = { "ーーーーーー": "ーーーーーー", "ーーーーー": "ーーーーー", "ーーーー": "ーーーー", "ーーー": "ーーー", "ーー": "ーー", } # ユーザー辞書 user_dictionary_list = [ { "アストラル": "アストラル", "AIMS": "AIMS", }, { "ー登": "一登", "タ姫羽": "夕姫羽", "ニコル": "ニコル", "亮ー": "亮一", "カルマルカ": "カルマルカ", }, { "ソフィー": "ソフィー", "リグ・ヴェーダ": "リグ・ヴェーダ", "与ー": "与一", "ゴースト": "ゴースト", }, { "ニ乃": "二乃", "ー登": "一登", }, { "リッカ": "リッカ", }, { "良ー": "良一", }, { "ー葉": "一葉", }, { "オリエッタ": "オリエッタ", "シャロン": "シャロン", "メアリー": "メアリー", "イスタリカ": "イスタリカ", }, { }, ] my_app( r"mtlmr3m", r"mtlmr3m\log_logs\version_5", system_dictionary, user_dictionary_list, )
「ぺ」の追加検証
別のデータセットを試す前に例の不思議トークン「ぺ」の検証を済ませちゃいます。
検証内容としては以下の通りです。
1は失敗に終わりそうな気もしますが一応調べてみます。
検証用に一部のコードを改修します。
大元のデータクラスの改修は検証結果次第なため、
とりあえず空白トークンである10234を「ぺ」として分類できるように辞書にぶち込んでおきます。
# train.py mask_ids = list(similar.converted_similar_tokens.values()) mask_ids += [10234]
# test.py similar_label = similar.similar_label similar_label["ぺ"][10234] = "ぺ"
推論結果は以下のとおりです。
| epochs | origin | 1 | 2 |
|---|---|---|---|
| 1 | 2610 / 2584 / 26 | 2610 / 2591 / 19 | 2610 / 2590 / 20 |
| 2 | 2610 / 2587 / 23 | 2610 / 2591 / 19 | 2610 / 2591 / 19 |
| 3 | 2610 / 2589 / 21 | 2610 / 2592 / 18 | 2610 / 2592 / 18 |
| 4 | 2610 / 2590 / 20 | 2610 / 2593 / 17 | 2610 / 2593 / 17 |
| 5 | 2610 / 2593 / 17 | 2610 / 2594 / 16 | 2610 / 2594 / 16 |
| 6 | 2610 / 2595 / 15 | 2610 / 2595 / 15 | 2610 / 2595 / 15 |
10234を含んで学習、推論をした方が早期に収束していることが分かりました。
推論時に10234を「ぺ」として認識するか否かの差分は無さそうですね。
やはりこのトークンは学習時に重要視されるものなのでしょうか。
設計者ではないので真相は分かりませんが結果を見る限りはその可能性が高そうですね。
そしてやはりですが、精度の高止まりしてますね。
収束が早いとこういった問題点が明らかになるタイミングも早くなるので色々と助かります。
一概に収束が早ければいいという訳ではないことは理解していますが個人開発下においては割と重要。
結果をまとめると、
学習時には10234をマスク化対象に入れるべきで、
推論時には10234を「ぺ」として認識しても良い、
ただし精度に大きな差分は発生しないといった感じです。
wikipediaとoscarデータセットを試す
これまでの結果から類似文字推定特化な学習と運用に大きな問題がないことを確認できました。
しかしデータセットが軽量なため精度の高止まりが発生しています。
というわけで別のデータセットで学習してみます。
使用するデータセットはwikipediaデータベースとoscarデータセットの2つです。
それぞれの特徴としてwikipediaは教科書や辞書に載っているような規則正しい文章が多いのに対して、
oscarは口語などの日常で使われる内容も多く含まれる汎用性の高いデータセットなイメージです。
これら2つのデータセットを部分的に学習させる方法で進めます。
フルサイズを学習しようとしたら画像のようにイカれた学習時間が算出されたので諦めました。

データセットまわりの解説は省略して早速、学習と推論結果を見てみます。
WikiExtractorや先ほどまでのプリプロセスを並列化していたり意外と内容がボリューミーなので省略です。
別の機会に解説予定です。たぶん。
学習には1エポックで4時間ほどかかりました。
| epochs | 精度 |
|---|---|
| 1 | 2610 / 2608 / 2 |
1エポックまわすだけで結構な精度が出ました。
やはりBERT系はデータ量の依存関係強いですね。
精度が高くなったことは嬉しいのですが、1エポック4時間は個人開発環境ではチューニングしきれないサイズですね。
精度が9割超えれば実用に大きな支障はないので筆者的には燃え尽き症候群が発症する程度には満足しました。
おわりー。
ちなみに類似文字推定は画像な感じで使ってます。

おわり!!!
お疲れさまでした!!!
最終的には高精度な類似文字推定モデルが完成してよかったです。
今回は部分的に解説チックな構成にしてみました。
後半は飽きちゃったので普段の温度感に戻ってますが。
今までは筆者の書きたいことを殴りつけて満足しちゃうのですが、たまにはこういった真面目な構成もいいですね。
真面目な構成は書く手間が普段のn倍なのが面倒なのですが、
普通に復習にはなるので意外と良いです。でもやっぱりめんどう。
さて、これだけ長々と検証したり実装したりしましたが、今時はChatGPTに質問すれば解決なんでしょうね。
筆者は趣味でコードを書いているので流行りに影響されずに好きなことをできますが、
NLPに関わることをお仕事にしている方々はChatGPTの登場で環境変化エグそう。
頑張ってくださいの一言に尽きますわ。
参考
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[1706.03762] Attention Is All You Need
[1910.01108] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
GitHub - BandaiNamcoResearchInc/DistilBERT-base-jp
GitHub - line/LINE-DistilBERT-Japanese: DistilBERT model pre-trained on 131 GB of Japanese web text. The teacher model is BERT-base that built in-house at LINE.
高性能・高速・軽量な日本語言語モデル LINE DistilBERTを公開しました
GEM/wiki_lingua · Datasets at Hugging Face
tyqiangz/multilingual-sentiments · Datasets at Hugging Face
マスク言語モデルの微調整 - Hugging Face NLP Course