こんにちは!!!クライアントエンジニアの小林です。
今回はSageMaker Serverless Inferenceを使用してPyTorchな推論モデルをサーバーレスで動かしていきます。
- 作業環境
- 概要
- SageMaker Serverless Inferenceとは
- SageMaker Serverless Inferenceの料金プラン
- 流れ
- モデルと推論コードの準備
- ファイルのアップロード
- モデルのデプロイ
- Lambdaの構築
- API Gatewayの構築
- ローカルから動作テスト
- おわり!!!
- 参考サイト
作業環境
・windows 10
・visual studio code
・python 3.9.12
概要
SageMaker Serverless Inferenceを使用してPyTorchな推論モデルをサーバーレスで動かしていきます。
例としてCRAFTを扱います。
CRAFTはざっくりいうと文字領域検出モデルです。
あくまでサーバーレス推論をすることがメインなのでモデルの詳細は省きます。

アーキテクチャはこんな感じです。
あれだけサービスあるのになぜ公式で作図ツールを用意していないのだ。
- 画像を送信
- APIGatewayでLambdaで送りつける
- Lambdaからサーバーレス推論の呼び出し
- 推論結果をLambdaで受け取り
- APIGatewayで画像の送信元に結果を投げつける

注意点として筆者はAWSと初対面な上にあまり仲良くありません。
サーバーレス推論をするために触った程度です。
そのため「動けばええやろ」精神で、各項目の設定は必要最低限となっています。
SageMaker Serverless Inferenceとは
SageMakerはAWSが提供している機械学習プラットフォームです。
その中のサービスの1つServerless Inferenceがサーバーレス推論というわけです。
SageMaker Serverless Inferenceの料金プラン
料金は推論にかかった時間とデータの送受信量に依存します。
おそらくモデルの起動時間も含まれる気がします。どうせケチだから。
流れ
こんな感じで進めます。
流石に機械学習専用サービスなだけあってフロー自体もシンプルです。
モデルと推論コードの準備
SageMakerで動作するコード一式を用意します。
モデル実装
基本的にはローカルで動かしているものを流用できます。
例としてCRAFTの実装コードを載せています。
注意点として2023/03/06時点のSageMaker for PyTorchのPythonバージョンは3.8です。
型ヒントに旧仕様であるtypingモジュールを使う必要があったり、dictやlistの結合にoperatorが使えなかったりと、3.8以降のバージョンを使っている場合はダウングレード対応が発生します。
その他にもGPU推論が非対応だったりします。
追加のパッケージ指定
SageMakerに標準インストールされていないパッケージはpip installでお馴染みなrequiments.txtに指定する必要があります。
CRAFTは標準モジュールで事足りるため、実際のデプロイには含めませんが、分かりやすいように画像では配置した状態で撮っています。
学習済みモデルの用意
サーバーレス推論のお試し用としてCRAFTの学習済みモデルを公開しています。
公開している学習済みモデルはCC BY-NC 4.0を適用しています。
ImageNetを元に学習したvgg16モデルを使用している関係で非営利にしています。
SageMaker PyTorch Model Server
PyTorch LightningやHugging FaceのようにSageMakerにはSageMakerのフレームワークが存在します。
SageMakerのフレームワークに対応した関数を定義していればそれが実行され、未定義の場合はデフォルトの関数が実行されるといった、挙動的にはC系のオーバーライドと同様です。
詳しくはこちらのドキュメントに載っています。
ファイルを圧縮
先ほど用意した学習済みモデルですが、pth形式でのアップロードはできません。
これをtar.gz形式で圧縮する必要があります。
そして圧縮時に先ほど実装したinference.pyやcraft.py、requiments.txtなどを含めることでデプロイ時の作業が減ります。
作業自体は減るのですがコーディングミスや不具合修正をするたびに再圧縮をする必要が発生します。
そのためpython初心者にはむしろ悪手だったりします。
今回はデプロイ設定を最低限で行いたいので圧縮時に必要なファイルをすべて突っ込んでいますが、慣れない方はデプロイ時に行う方法も試してみてください。
今回は紹介しませんが先ほどのドキュメントになんとなく載っているので、たぶんそれで理解できます。
前置き長くなりました。
rootフォルダに学習済みモデルを配置、rootフォルダにcodeフォルダを作成します。
codeフォルダにはモデル実装ファイルやinference.py、requiments.txtを突っ込みます。
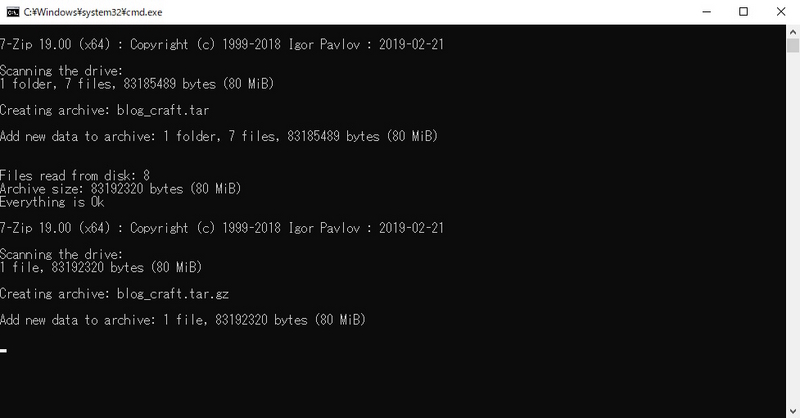
rootフォルダを右クリックで圧縮なのですが、操作手順が面倒なので適当にスクリプトを作ります。
メモ帳にコードを貼り付けて、いくつかの変数を変更した後に*.bat拡張子で保存、実行することで動作するはずです。
HatenaBlogSample/pack-blog-craft.bat at sagemaker-serverless-inference/main · spark-kobayashi-arata/HatenaBlogSample · GitHub
実行するとROOT_DIRにtar.gz形式のファイルができていると思います。

ファイルのアップロード
tar.gz形式に圧縮したファイルをS3にアップロードします。


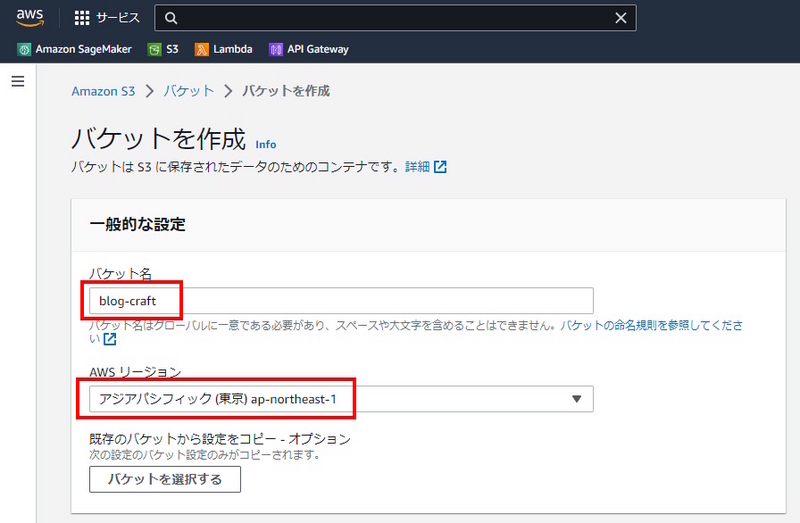
アップロード





モデルのデプロイ
S3にアップロードしたファイルを元にSageMakerノートブックインスタンスからサーバーレス推論モデルをデプロイします。
デプロイが完了したらそのモデルが正常に動くか軽く動作テストをします。
ノートブックインスタンスの作成






モデルのデプロイ

上記のコードを貼り付けて実行します。
model_data引数にはS3にアップロードしたファイルのS3 URIを指定する必要があります。


!マークが末尾に出たらデプロイ完了の合図です。
Notebookで動作テスト

上記のコードを新しいセルに貼り付けます。
CRAFT_ENDPOINTにはデプロイしたモデルのエンドポイント名を指定します。

これをCRAFT_ENDPOINTに指定します。

画像は公開している学習済みモデルに含まれるsample2.pngを使用しています。

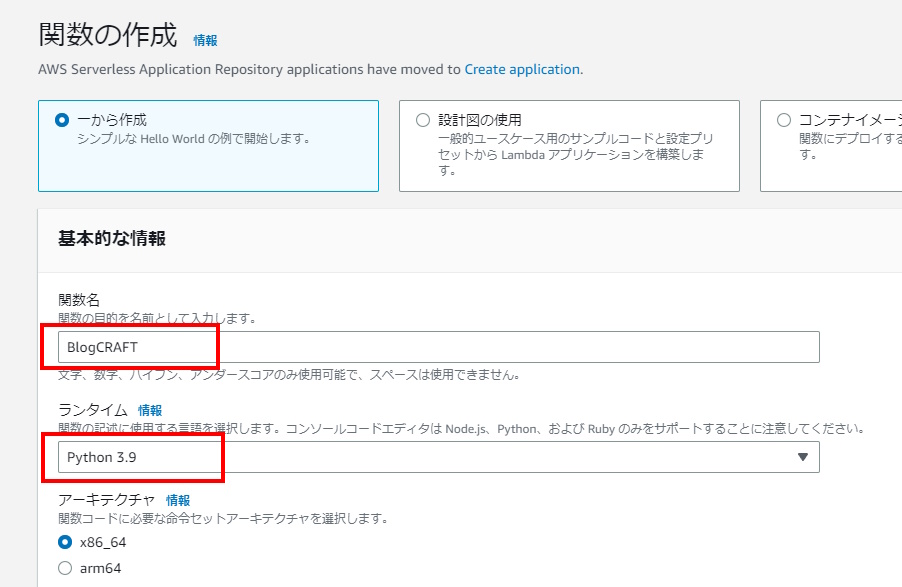
Lambdaの構築
主にサーバーレス推論の呼び出しを行います。

モジュールの追加
素のLambda for Pythonでは主要モジュールであるnumpyやboto3などがインストールされていません。
そのため不足しているモジュールをインストールするためにレイヤーを使用します。
リポジトリで公開されているものを使用しました。感謝。
なんでこういうの公式で用意しないんでしょうか。Amazonさんの怠慢ですね。



arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-p39-boto3:11
『ARNを入力』>『検証』>『追加』の順番です。

コードの実装

上記のコードをlambda_function.pyに貼り付けます。

タイムアウトの変更
先ほども少し触れましたがサーバーレス推論はGPU非対応です。
それ故に推論には数秒要します。
Lambdaのデフォルトタイムアウトは3秒です。
つまり余裕でタイムアウトします。
そのためタイムアウトを30秒に変更します。
Lambda自体は30秒以上待ってくれるのですが、後述するAPIGatewayが最大で29秒しか待ってくれないため30秒です。
モデル読込を含むと30秒超えることもあるので地味に厳しい縛りです。


アクセス権限の付与
LambdaからSageMakerにアクセスするためには権限付与が必要です。
付与する権限は『推論モデルの実行のみ』でいいのですが、面倒なので適当にフルアクセス権限を付与しちゃいます。







アクセス権限の付与(SageMaker)
Lambdaと同様にSageMakerにもアクセス権限を付与する必要があります。
たぶん。。。
というのも元から追加されていたのか、自分で追加したのか、もはや覚えてないのです。



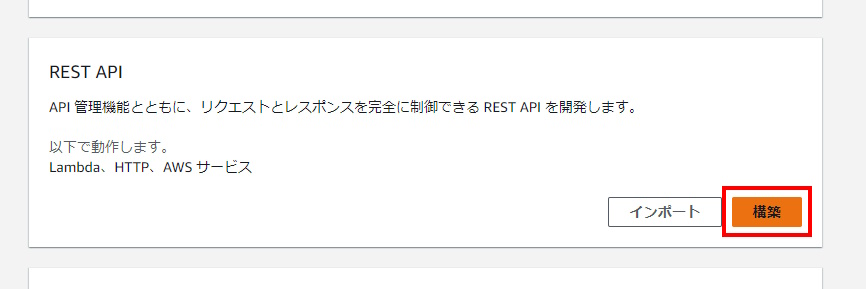
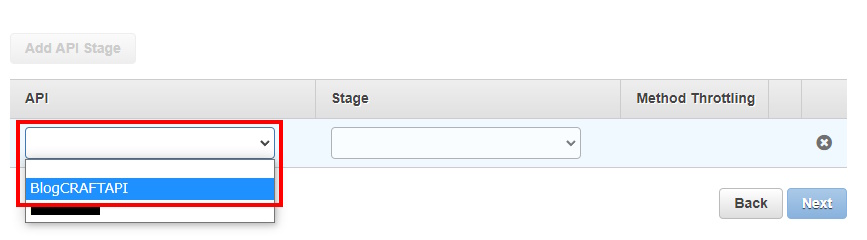
API Gatewayの構築
リクエストとレスポンスを可能にするREST APIを構築します。



Lambda関数と紐づけ







APIキーの作成と適用
アクセス制限を設けるためにAPIキーによる認証を設定します。




API keyはコピーしておいてください。

『Method Request』を選択します。




デプロイ




Invoke URLはコピーしておいてください。
APIキーの紐づけ


Nameを入力後、『Enable throttling』と『Enable quota』のチェックを外して制限を解除します。
注意点として不特定多数の利用者を想定した場合は外さずに設定しないと危ないです。










ローカルから動作テスト
HatenaBlogSample/request.py at sagemaker-serverless-inference/main · spark-kobayashi-arata/HatenaBlogSample · GitHub
上記のコードを実行します。

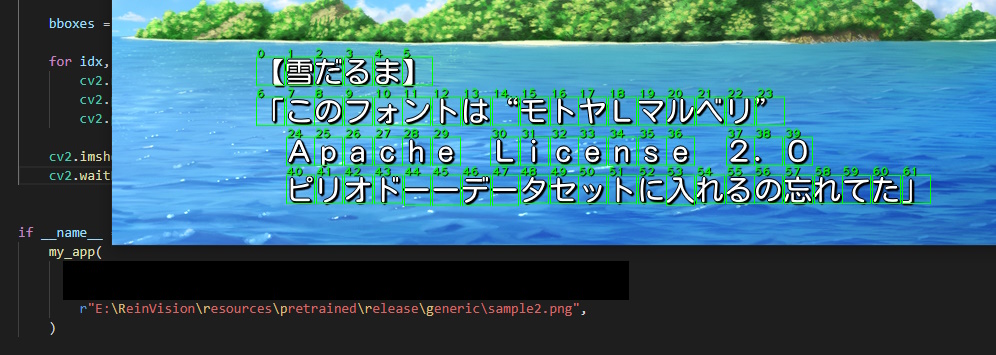
できた。vいえーいv
おわり!!!
お疲れさまでした!!!
一番疲れたのは筆者ですが。
数ヶ月後の自分用に画像マシマシで作ったはいいものの後半になるにつれて飽きがヤバかったです。
Serverless Inferenceはサーバーを知らぬ人でも構築できる良きサービスです。
ただ、GPU非対応だったり、複数モデルを同時に扱えなかったり、すぐにスリープ状態に入ったりと実運用するには不向きなんだろうなと感じました。
試験的なモデルの共有や簡易的なサンプル、推論頻度が低いモデルなどには最適なのでしょう。
とはいえ最近(2023/03/12)のAI需要的にAmazonさんも優先的に改善していくべきサービスなのではないかなと予想していたりします。
せめてGPU推論はできるようにしてほしいです。