こんにちは!!!クライアントエンジニアの小林です。
今回はTesseractのFineTuningをWindows環境で実行する方法をまとめました。
目次
概要
windows仕様に書き換えたtesstrainの実行方法の解説です。
作業環境
・windows10
・visual studio code
・python 3.9.12
・Tesseract 5.2.0
Tesseractのインストール
Home · UB-Mannheim/tesseract Wiki · GitHub
上記のサイトにアクセスしインストーラをダウンロードします。
リポジトリの取得
リポジトリを取得する前に改行コード自動変換機能をオフにします。
設定や確認方法は以下のサイトを参照ください。
【Git】改行コードが自動変換されてしまう対処法〜Windowsでチェックアウト・コミット時の注意 | Techs Report
サイトが消えた時用のメモ
設定方法
git config --global core.autocrlf false
確認方法
git config --global -l
core.autocrlf=falseでオフになっている
なぜオフにする必要があるのかというと。
リポジトリ上のtesstrainやlangdataなどの改行コードはLFとなっており、training-toolの改行コードもLF前提で動作しています。
そこにCRLFをぶち込むと、どこかのタイミングでデシリアライズできねぇ!!!と怒るからです。
改行コード自動変換機能をオフにしたら必要なリポジトリを落とします。
今回はgitコマンドでちょちょいとやります。
cd /d e:\ git clone --recursive -b for_windows https://github.com/mona511/tesstrain.git
1行目はカレントディレクトリをEドライブに移動しています。
今回はEドライブとしていますが、場所はユーザーの任意で問題ありません。
2行目がクローンコマンドです。
--recursiveはサブモジュールを含んでいるので再帰的なオプションを有効にしています。
-b for_windowsはfor_windowsブランチを指定しています。
サブモジュールを含んでいるのでクローンは少し時間が掛かるはずです。
venv環境の構築
cd tesstrain py -3.9 -m venv .venv cd .venv/scripts activate pip install -r ../../requirements.txt
1行目はクローン先に移動。
2行目はpython3.9でvenv環境を作成。
3行目はactivate.exeがあるディレクトリに移動。
4行目でactivate.exeの呼び出し。
5行目でライブラリのインストールをしています。
ライブラリといってもhydraぐらいしかないわけですが。
実行方法
train.pyをvscodeから実行する方法とコマンドプロンプトからの2種類用意してあります。
vscodeから実行する場合はlaunch.jsonのargsに指定し、コマンドプロンプトの場合は引数指定するだけです。


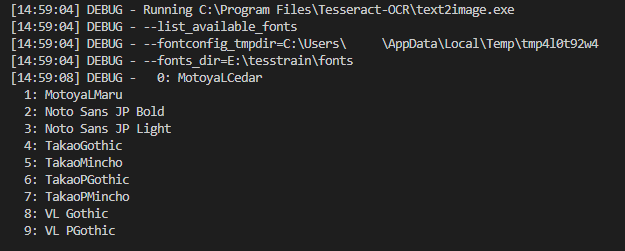
Stage0: 使用可能なフォント一覧の表示
training-toolが認識できるフォントかを調べたり、フォント名を確認する際に使用します。
準備
tesstrainフォルダ内にfontsフォルダを作成し、そこにフォントファイルを配置します。
権利の関係でリポジトリにはフォントファイルは一切含まれていないので各自で用意する必要があります。

コマンド引数
--stage 0 --config "E:\\tesstrain\\conf\\config.yaml
config
| パラメータ | 説明 | 初期値 |
|---|---|---|
| fonts_dir | フォントフォルダのディレクトリを指定 | tesstrain\\fonts |
実行結果
ここに表示されたフォント名が学習に使用できるフォントです。
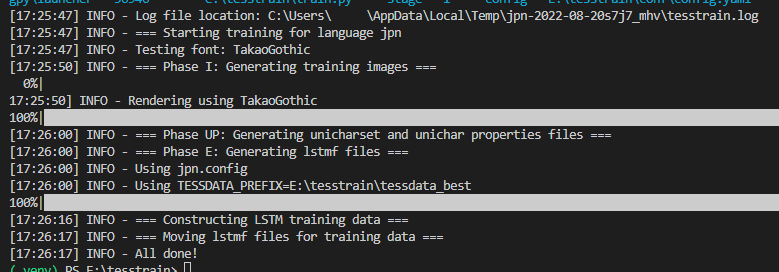
Stage1: lstmデータの作成
指定されたフォントとテキストを元に、FineTuningに必要なデータを作成します。
準備
training_textを用意する必要があります。
tesstrain\\langdata\\jpn\\jpn.training_textを適当なディレクトリにコピペします。
今回はtesstrain\\data\\jpn.training_textにコピペしています。
直に書き換えても問題はないのですが、オリジナルが行方不明になるのは微妙に不便なためコピペしています。

tesstrain\\data\\jpn.training_textに追加で学習させたい文字を適当に追加します。
training_textを編集する際に気を付けることが、文字コードをUTF-8、先ほども触れた改行コードをLFにすることです。
この設定を変えるとtraining-toolが動作しません。
また、追加したい文字は最低でも4回以上出現するように調整する必要があります。
langdataについて
for_windowsブランチに含まれているlangdataは学習コストの低い方のlangdataです。
高精度なlangdata_lstmというのもあるので、お好みのほうを使ってみてください。
それぞれの違いとして、
・langdataは対応漢字が多いが精度が微妙
・langdata_lstmは対応漢字がlangdataより少ないが精度が高い
ただし、langdata_lstmは学習にかかる時間がlangdataの比ではありません。
それもそのはずでlangdataのjpn.training_textが153 KBに対し、langdata_lstmは26.9 MBあります。
本来であればFineTuningをする場合はlstmが適切なのですが、学習時間がどえらいのでとりあえずlangdataでフローを試してからlangdata_lstmに挑戦するのがいいかもしれません。
コマンド引数
--stage 1 --config "E:\\tesstrain\\conf\\config.yaml
config
| パラメータ | 説明 | 初期値 |
|---|---|---|
| console_level | コンソール出力レベル | info |
| lang | 言語を設定 | jpn |
| fonts | 使用するフォントを指定 | TakaoGothic |
| langdata_dir | langdataのディレクトリを指定 | tesstrain\\langdata |
| tessdata_dir | tessdataのディレクトリを指定 | tesstrain\\tessdata_best |
| training_text | 学習させるテキストのパスを指定 | tesstrain\\langdata\\{config.lang}\\{config.lang}.training_text |
| output_dir | 出力先 | Tempフォルダ |
| ptsize | フォントサイズ | 12 |
| save_box_tiff | lstmデータ作成に使用したフォント画像を保存するか | False |
| tesstrain_args | 上記に含まれないオプションを指定、文字間隔のchar_spacingなど | None |
実行結果
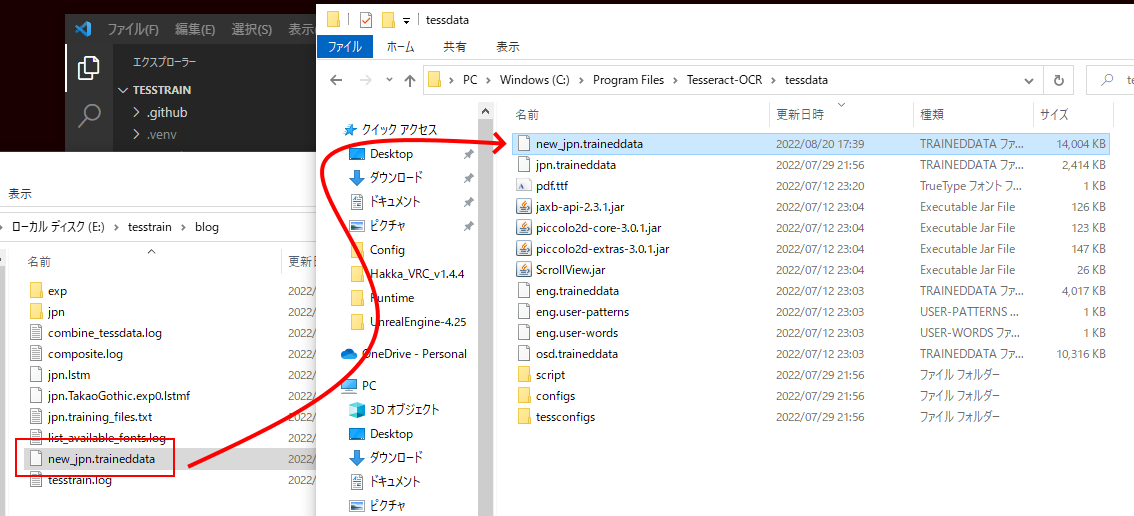
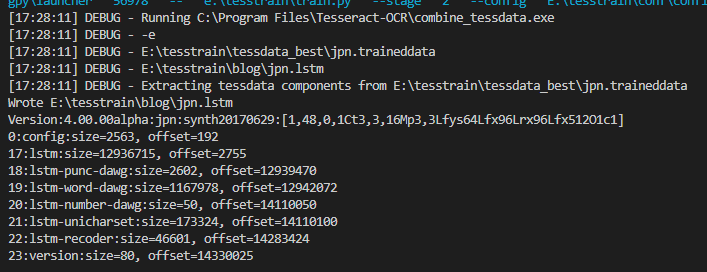
Stage2: CombineTessdata
FineTuningに必要なデータ作成その2です。
コマンド引数
--stage 2 --config "E:\\tesstrain\\conf\\config.yaml
config
stage1と同様です。
実行結果
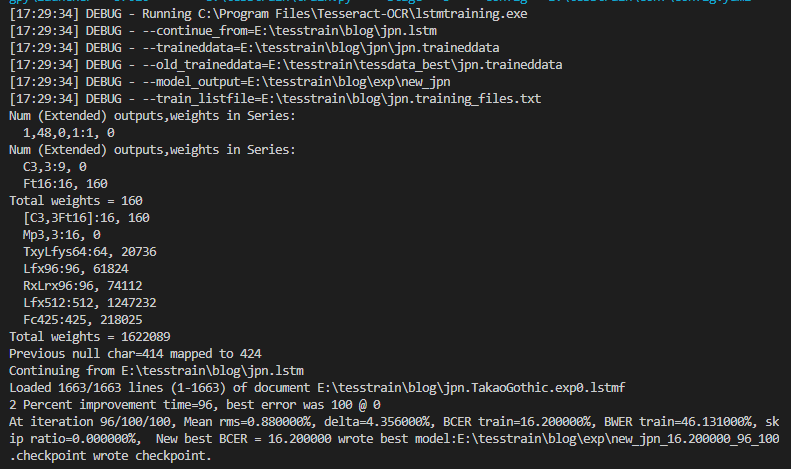
Stage3: FineTuning
FineTuningします。
長いです。
待ちましょう。
コマンド引数
--stage 3 --config "E:\\tesstrain\\conf\\config.yaml
config
| パラメータ | 説明 | 初期値 |
|---|---|---|
| new_lang | FineTuningで新しく作成するlang名を指定 | new_{config.lang} |
| max_iterations | 最大イタレーション数を指定 | None |
実行結果
Stage4: Composite
学習結果からtraineddataを作成します。
コマンド引数
--stage 4 --config "E:\\tesstrain\\conf\\config.yaml
config
| パラメータ | 説明 | 初期値 |
|---|---|---|
| checkpoint | どのcheckpointからtraineddataを作成するかを指定 | {config.new_lang}_checkpoint |
実行結果