こんにちは!!!クライアントエンジニアの小林です。
今回はPythonの定期実行プログラムをHerokuで動かす方法をご紹介します。
シンプルな定期実行プログラムの他に、
herokuアドオンを2つほど使ったコードをそれぞれ紹介していきます。
私の作業環境
- windows 10
- visual studio code
- github
- source tree
- python 3.9.1 ~ 3.10.2
シンプルな定期実行プログラム
サンプルコード
main.py ... main.py
requirements.txt ... 使用するライブラリをバージョンとセットで指定
Procfile ... アプリ起動時に呼び出す.pyを指定
main.py
import sys import signal import datetime as dt from apscheduler.schedulers.blocking import BlockingScheduler class MyApp: def __init__(self): pass def process(self): print("hello world :)") # SIGTERMの受取先が無いと警告としてカウントされる対応策 def signal_handler(signal_number, frame): sys.exit(0) # スケジューラー scheduler = BlockingScheduler() # シグナルハンドラを登録 signal.signal(signal.SIGTERM, signal_handler) # my_app my_app = MyApp() # 1時間毎に実行 @scheduler.scheduled_job("cron", minute=0, second=5, timezone=dt.timezone.utc) def my_app_1h_job(): my_app.process() # 4時間毎に実行 @scheduler.scheduled_job("cron", hour="0,4,8,12,16,20", minute=0, second=5, timezone=dt.timezone.utc) def my_app_4h_job(): my_app.process() scheduler.start()
requirements.txt
APScheduler==3.9.1
Procfile
main: python main.py
コード説明
signal関数
def signal_handler(signal_number, frame): sys.exit(0) signal.signal(signal.SIGTERM, signal_handler)
シグナル関数を書かないとアプリが終了するたびに、
"シグナルの受取先がないよ"警告が出力されます。
書かなくても動作はしますが、
定期的に警告が発生しているのは気分が悪いと思うので、
特に意味はなくとも書いておくことをおすすめします。
"特に意味はない"と書きましたが、意味を持たせることもできます。
上記のコードでは、アプリ終了時にシグナル関数が呼ばれ、sys.exitが実行されます。
なのでsys.exitの前に任意の関数を仕込むことでそれを実行させることができます。
def signal_handler(signal_number, frame): print("b") sys.exit(0)
イベント系の処理を簡単に実装できるのは助かりますね。
1つ注意点として、
終了時に呼ばれるシグナル関数は、
一定時間が経過するとたとえ処理が走っていようが強制終了します。
APSchedule
"python 定期実行"で調べてくると出てくるあやつです。
このライブラリのおかげで実行環境とプログラムの用意だけで定期実行が実現できます。
Pythonは本当にすごいですね。
デコレータで@scheduler.scheduled_jobを記述した関数が定期実行されます。
cronが定期実行
minuteとsecondといった時間系が定期実行のタイミング
timezoneは実行タイミングのタイムゾーン指定です。
@scheduler.scheduled_job("cron", hour="0,4,8,12,16,20", minute=0, second=5, timezone=dt.timezone.utc)
この場合は日本時間ではなく、
utc時間の0,4,8,12,16,20時と5秒に実行してね。と指定しています。
timezone
タイムゾーンについて少しだけ。
herokuで現実時間を扱う際にはutc基準で設計をすることをおすすめします。
細かな理由を挙げていると長くなるので箇条書きにしますが。
- アプリのローカル時間がおそらくリージョンや言語設定によって異なる。
- ローカル時間を設定できるが、謎のタイミング(メンテや原因不明)でリセットされることがある。
- アプリを新規作成したら再設定しないといけないのでヒューマンエラーの原因になりうる。
- utcから任意のタイムゾーンに変換する機能がdatetimeに標準搭載されている。
UTCからJSTへの変換コード
変換時はutcnow()ではなく、
now()でタイムゾーンを指定するやり方を推奨しています。
JST = dt.timezone(dt.timedelta(hours=+9)) utcnow = dt.datetime.utcnow() jstnow = utcnow.astimezone(tz=JST) print("utcnow()") print(utcnow) print(jstnow) utcnow = dt.datetime.now(tz=dt.timezone.utc) jstnow = utcnow.astimezone(tz=JST) print("now(tz=dt.timezone.utc)") print(utcnow) print(jstnow)
utcnow() 2022-05-05 06:50:16.105882 2022-05-05 06:50:16.105882+09:00 now(tz=dt.timezone.utc) 2022-05-05 06:50:06.467882+00:00 2022-05-05 15:50:06.467882+09:00
データベースを利用した定期実行プログラム
Heroku Postgres
herokuでデータベースを利用する際には、
Heroku Postgresというアドオンを追加する必要があります。
アドオン追加手順
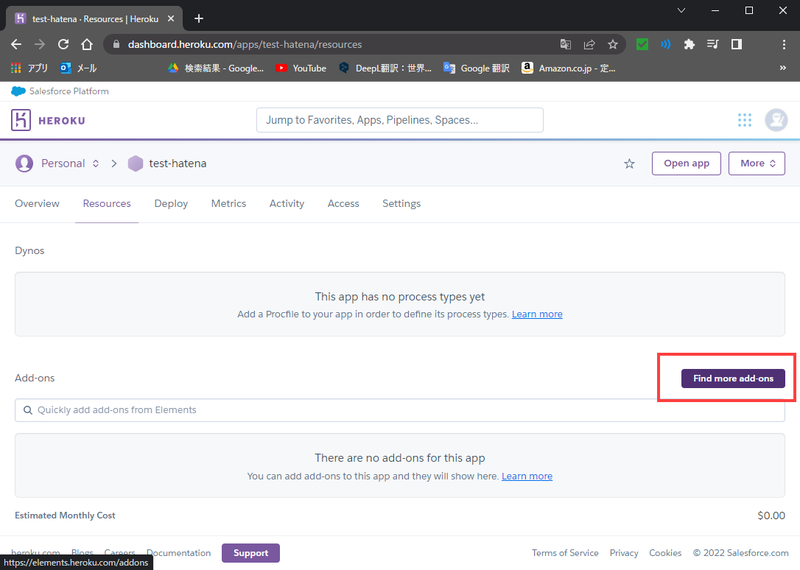 |
- Find more add-onsをクリック
- クリックするとページ移動します
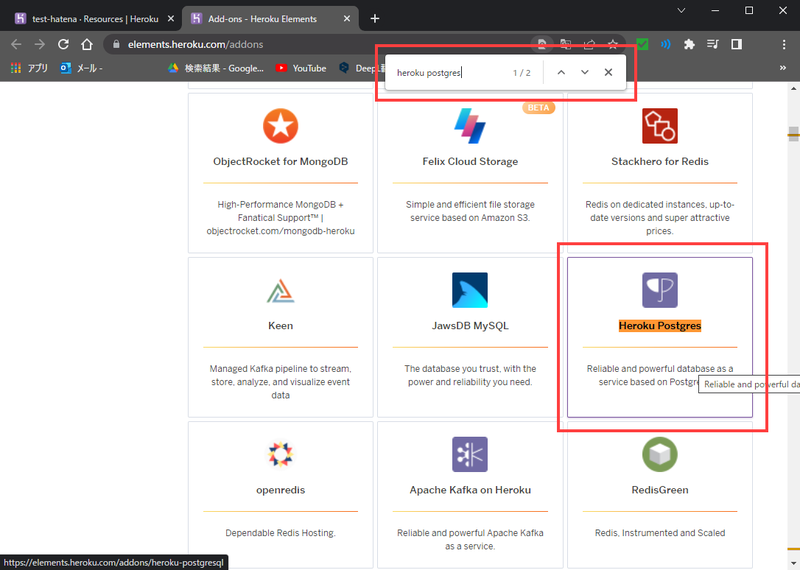 |
- Heroku Postgresを探してクリック
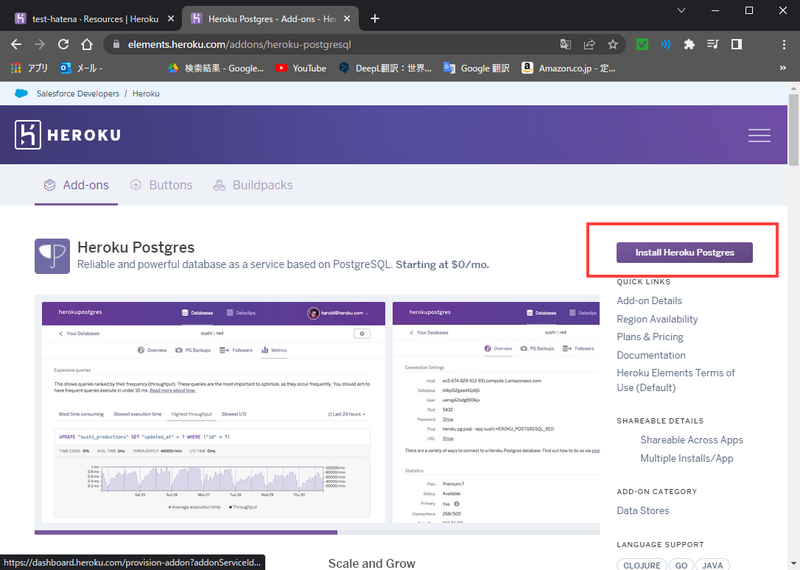 |
- Install Heroku Postgresをクリック
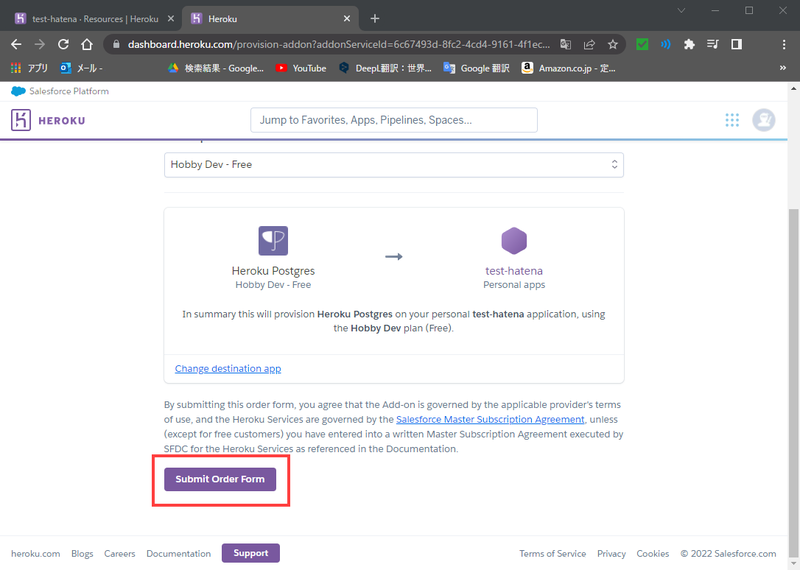 |
- App to provision toにアドオンを追加するアプリ名を入力
- ある程度入力すると候補が出てくるので、任意のものを選択
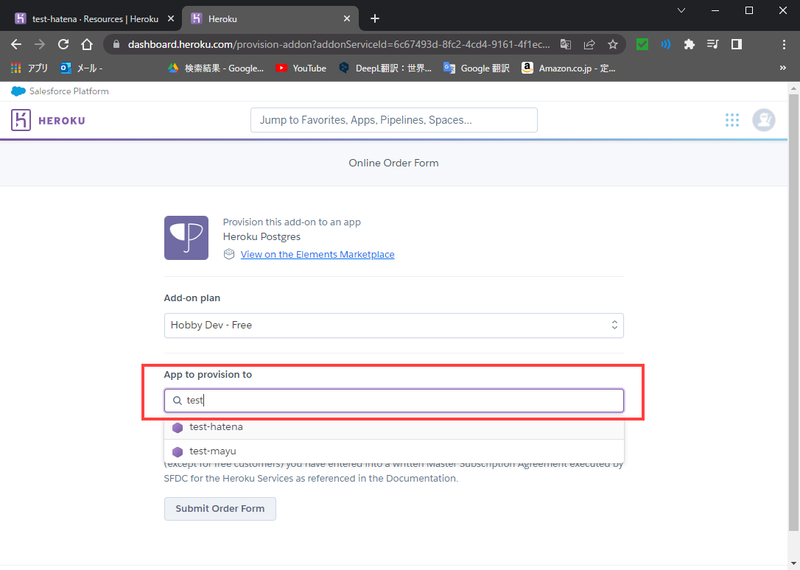 |
- Submit Order Formをクリック
 |
- 画像のようになっていれば追加完了です
 |
- Settingsページの環境変数を見ると
DATABASE_URLが追加されています
サンプルコード
main.py ... main.py
requirements.txt ... 使用するライブラリをバージョンとセットで指定
Procfile ... アプリ起動時に呼び出す.pyを指定
main.py
import os import sys import signal import datetime as dt from apscheduler.schedulers.blocking import BlockingScheduler from sqlalchemy import create_engine import pandas as pd class MyApp: def __init__(self): # データベースのURLを取得 # postgresをpostgresqlに置き換える self.__database_url = str(self.__get_heroku_config_var("DATABASE_URL")) self.__database_url = self.__database_url.replace("postgres","postgresql") # PostgreSQLのサーバー接続エンジンを作成 try: self.__engine = create_engine(self.__database_url) except Exception as e: raise Exception('failed to setup Engine.') def process(self): print("hello world :)") def __load_database(self, filename:str=""): """データベース読込 Args: filename (str, optional): 読込名. Defaults to "". Returns: pd.DataFrame: 読込に失敗した場合はNoneを返す """ try: return pd.read_sql(sql="SELECT * FROM %s;"%filename, con=self.__engine, index_col="index") except Exception as e: return None def __save_database(self, filename:str="", data:pd.DataFrame=pd.DataFrame()): """pd.DataFrameをデータベースに保存 Args: filename (str, optional): 保存名. Defaults to "". data (pd.DataFrame, optional): 保存対象. Defaults to pd.DataFrame(). """ try: data.to_sql(name=filename, con=self.__engine, if_exists="replace") except Exception as e: # 保存に失敗 pass def __get_heroku_config_var(self, key:str=""): """heroku環境変数を取得 Args: key (str, optional): 変数名. Defaults to "". Raises: Exception: 取得に失敗した場合 Returns: str: 数値系もstrで返されるのでcast必須 """ try: return os.environ[key] except Exception as e: raise Exception(f"environment variable '{key}' is unset.") # SIGTERMの受取先が無いと警告としてカウントされる対応策 def signal_handler(signal_number, frame): sys.exit(0) # スケジューラー scheduler = BlockingScheduler() # シグナルハンドラを登録 signal.signal(signal.SIGTERM, signal_handler) # my_app my_app = MyApp() # 1時間毎に実行 @scheduler.scheduled_job("cron", minute=0, second=5, timezone=dt.timezone.utc) def my_app_1h_job(): my_app.process() scheduler.start()
requirements.txt
APScheduler==3.9.1 pandas==1.4.1 SQLAlchemy==1.4.32 psycopg2==2.9.3
Procfile
main: python main.py
コード説明
URL修正
self.__database_url = str(self.__get_heroku_config_var("DATABASE_URL")) self.__database_url = self.__database_url.replace("postgres","postgresql")
heroku環境変数から取得したDATABASE_URLは、
文字列中の"postgres"を"postgresql"に置換しなければ使用できません。
SQLAlchemy
try: self.__engine = create_engine(self.__database_url) except Exception as e: raise Exception('failed to setup Engine.')
self.__engineは後述する関数の引数に渡します。
create_engineに失敗した場合は、
DBアクセスができないのでエラー落ちさせています。
herokuに限ったことではないと思いますが、
ある程度環境依存なエラーとかも起こりうるので、
その場合は下手に再試行するよりアプリをエラー落ちさせて、
再起動させた方が上手くいくことが体感的には多かったりします。
データベースから読込
def __load_database(self, filename:str=""): try: return pd.read_sql(sql="SELECT * FROM %s;"%filename, con=self.__engine, index_col="index") except Exception as e: # テーブルが存在しない return None
pd.read_sqlでDBにあるテーブルを取得します。
テーブルが存在しない場合は例外が発生するので、
新規作成やエラー落ちするなど要件にあった対応ができます。
3.9では"テーブルが見つからない"をProgrammingErrorでキャッチできていたのですが、
3.10ではキャッチしてくれなかったので、おとなしくExceptionにしました。
index_colは行番号に使用する列名を指定しています。
ここらへんは細かいので、公式のリファレンスかまとめ記事を見てください。
データベースに保存
def __save_database(self, filename:str="", data:pd.DataFrame=pd.DataFrame()): try: data.to_sql(=filename, con=self.__engine, if_exists="replace") except Exception as e: # 保存に失敗 pass
DataFrame.to_sqlでデータフレームをDBに保存します。
読込もそうですがpandasがDB操作をサポートしているので簡単ですね。
IP固定 + データベースを利用した定期実行プログラム
QuotaGuard Static IP's
データベース同様にアドオンを利用します。
追加手順は同じですが、追加後に利用規約に同意するステップが存在します。
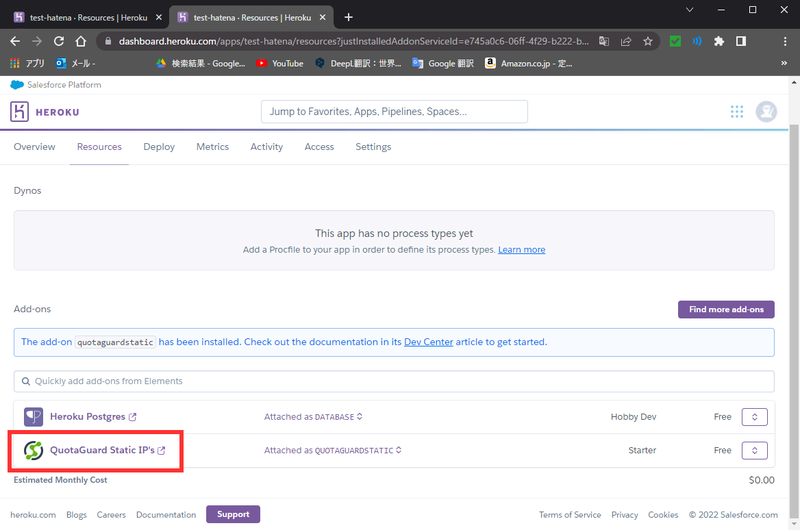
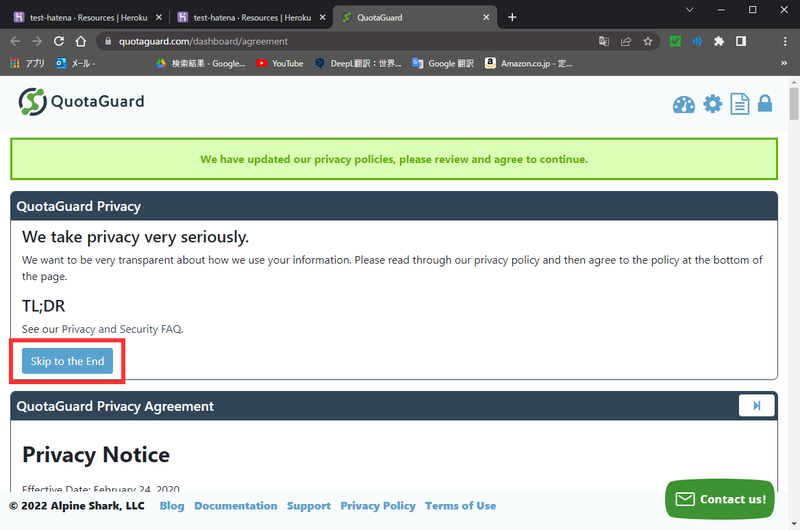
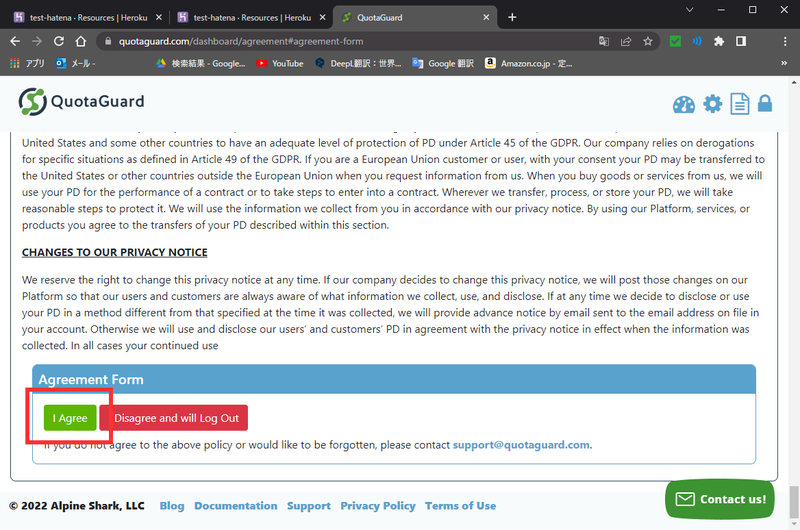
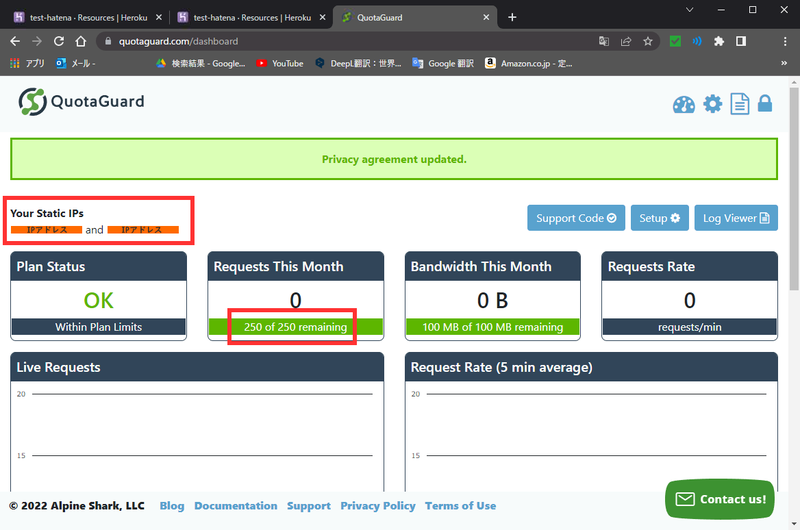
使い方
def __create_quota_guard_static_proxies(self): """QuotaGuard Static IP's Returns: dict: http, https """ result = { "http":self.__get_heroku_config_var("QUOTAGUARDSTATIC_URL"), "https":self.__get_heroku_config_var("QUOTAGUARDSTATIC_URL") } return result
静的IPアドレスを"http"と"https"に格納して、それをプロキシ変数にセットするだけです。
ここらあたりは、どのライブラリや関数を通しても同じなのではないでしょうか。
多少書式が異なるとかはあると思いますが。
私の場合は、公式が提供しているAPIをセットアップ後に、プロキシ変数にセットな感じです。
self.__pri_api = api() # setup self.__pri_api.proxies = self.__create_quota_guard_static_proxies() # static ip
アクセス数について
セットアップ画像の最後にチラッと書きましたが、
このアドオンには使用回数の制限があります。
フリープランでは250回、再安価の$9プランでは5,000回となっています。
アクセス数はget/postを1回実行するたびに1消費します。
# プロキシ未設定の場合はどんなにget/postしても使用回数は減らない self.pub_api.proxies = None self.pub_api.get_xxx() self.pub_api.post_xxx() # 静的IPを設定したプロキシをセットした場合は、get/postするたびに使用回数が1ずつ減る self.pub_api.proxies = self.__create_quota_guard_static_proxies() self.pri_api.get_xxx() self.pri_api.post_xxx()
おわり!!!
お疲れさまでした!!!