こんにちは!!!クライアントエンジニアの小林です。
趣味で触っているコーパス作成の過程でテキスト入力を自動化したいなぁと思いOCRを導入してみました。
cloud visionはAPI叩くスタイルなので鯖落ちとか面倒だなぁと思い、ローカルで動作するtesseractを選びました。
がしかし、tesseractさん、日本語に対する精度が低いです。
といっても英字は比較的読めているので読めないことはないだろうと思い、プリプロセスを頑張ったらギリギリ実用レベルに達しました。
今回はそれについてのご紹介です。
- 概要
- 作業環境
- 処理フロー
- SequenceMatcher
- TesseractCommon
- SimpleThreshold
- AdaptiveThreshold
- HybridThreshold
- Train
- demo
- tesseract-jpnが未学習な文字
- 終わり
- 今後
- Cloud Vision 試してみた
- 自作してみた
- 参考サイト
概要
特定の動作環境下においてtesseractの精度を上げる方法をご紹介します。
汎用性を求める方は巷で有名なGoogleさんのサービスを使うことをおすすめします。
精度が桁違いなので。やはりデータ量は正義なのですね。
流れとしてはコード全文、一部を抜粋して解説としています。
コードだけを見たい方はコード全文をコピペしてください。
作業環境
・windows10
・visual studio code
・python 3.9.12
処理フロー
- cv2.thresholdで2値化した画像に対してOCRを行います。
以降cv2.thresholdな処理をSimpleThresholdと呼びます。
2値化に使用するパラメータは、
初回は設定された範囲の値を全て使う総当たり方式で、
2回目以降は前回の結果から精度の高いパラメータのみを使用します。 - 1と同様のことを行います。
異なる点は使用する2値化関数をcv2.adaptiveThresholdに変えることです。
以降cv2.adaptiveThresholdな処理をAdaptiveThresholdと呼びます。 - SimpleThresholdとAdaptiveThresholdの結果から一定以上の精度のパラメータを使用し、
それらで組み合わせられる全てのパラメータでOCRを行います。
以降SimpleThresholdとAdaptiveThresholdを組み合わせた処理をHybridThresholdと呼びます。 - 以上をテスト画像毎に行うことで徐々に最適なパラメータが絞られていく感じです。
シンプルで愚直な方法ですが、それなりに精度を高めることができます。
SequenceMatcher
class SequenceMatcher: KOMOJI_SPL = { "ぁ":"あ", "ぃ":"い", "ぅ":"う", "ぇ":"え", "ぉ":"お", } KOMOJI_SPL_KEYS = tuple(KOMOJI_SPL.keys()) SYMBOL_SPL = { "『":"「", "』":"」", "「":"『", "」":"』", } SYMBOL_SPL_KEYS = tuple(SYMBOL_SPL.keys()) def __init__(self, a:str, b:str, use_only_length:bool=False): """コンストラクタ Args: a (str): _description_ b (str): _description_ use_only_length (bool, optional): 一致率を計算する際にAの長さしか考慮しないか. Defaults to False. """ self.a = a self.b = b self.use_only_length = use_only_length def __equal(self, a:str, b:str) -> bool: try: temp_a = a[0] except Exception: temp_a = None try: temp_b = b[0] except Exception: temp_b = None if temp_a == temp_b: return True elif temp_a in self.KOMOJI_SPL_KEYS and self.KOMOJI_SPL[temp_a] == temp_b: return True elif temp_a in self.SYMBOL_SPL_KEYS and self.SYMBOL_SPL[temp_a] == temp_b: return True elif temp_a is not None and temp_b is not None: return self.__equal(a, b[1:]) return False def ratio(self) -> float: if len(self.a) == 0 and len(self.b) == 0: return 1 if len(self.a) == 0 or len(self.b) == 0: return 0 success_count:int = 0 for i in range(len(self.a)): if self.__equal(self.a[i:], self.b[i:]): success_count += 1 if self.use_only_length: return (2*success_count)/(len(self.a)*2) else: return (2*success_count)/(len(self.a)+len(self.b))
ひらがな小文字や記号を区別するか
if temp_a == temp_b: return True elif temp_a in self.KOMOJI_SPL_KEYS and self.KOMOJI_SPL[temp_a] == temp_b: return True elif temp_a in self.SYMBOL_SPL_KEYS and self.SYMBOL_SPL[temp_a] == temp_b: return True
探している文字がひらがな小文字や記号一覧に含まれているかを、まずはkeyで判定して、含まれているのであればその後にvalueと比較しています。
ここではひらがな小文字と記号を別々の変数に分けていますが、処理速度を優先するのであればひとつにまとめたほうがいい(はず)です。この処理に限っては見やすさを優先しているので分けています。
ゲシュタルトパターンマッチングのスコア算出方法の追加
if self.use_only_length: return (2*success_count)/(len(self.a)*2) else: return (2*success_count)/(len(self.a)+len(self.b))
通常の計算方法がaとbの文字列の長さを足したもので除算するのに対し、今回追加したのはaの文字列の長さを2回足したものを除算する方法です。
これを実装することにより、鍵括弧内の文字だけあっていれば正解とする、といった運用ができます。
| a (training_text) | b (test_text) | use_only_length=False | use_only_length=True |
|---|---|---|---|
| こんにちは | 「こんにちは」 | 0.8333 | 1.0 |
| えっ | 「えっ!?」 | 0.5 | 1.0 |
TesseractCommon
import pyocr import pyocr.builders import pyocr.tesseract import numpy as np from PIL import Image from sequence_matcher import SequenceMatcher # regist path pyocr.tesseract.TESSERACT_CMD = r"C:/Program Files/Tesseract-OCR/tesseract.exe" # default tool OCR_TOOL:pyocr.tesseract = pyocr.get_available_tools()[0] # default text builder TEXT_BUILDER = pyocr.builders.TextBuilder(tesseract_layout=6) def image_to_string(srcs:list[np.ndarray], training_text:str, use_only_length:bool=False) -> tuple[float, str]: text:str = "" for src in srcs: text += OCR_TOOL.image_to_string(Image.fromarray(src), "jpn", TEXT_BUILDER) # remove symbol text = text.replace(" ", "") score = SequenceMatcher(training_text, text, use_only_length).ratio() return score, text
pyocr.tesseract.TESSERACT_CMD
環境変数に設定してある方は不要な記述です。
私は作業時にPCを再起動するのが面倒だったという理由から使用しそのまま使い続けています。
tesseract_layout
tesseract_layout=6は画像に含まれる複数行の文字を検出可能です。
tesseract_layout=7は画像を1行として文字検出を行うので精度が6よりも高いです。その代わり画像には文字が含まれていることを前提とした挙動をするので、何も書かれていない空の画像からも文字を検出し、結果的に誤検出につながります。
これは画像に含まれる有効ピクセル数の割合から回避することも可能ですが、今回は面倒なので一番シンプルに実装できるtesseract_layout=6で実装しています。
SimpleThreshold
import numpy as np import cv2 from dataclasses import dataclass from dataclasses_json import dataclass_json from tesseract_common import image_to_string @dataclass class SimpleThresholdParam: thresh:int=30 @dataclass_json @dataclass class SimpleThresholdResult: """ファイル入出力が発生するのでデータクラスにまとめている """ score:float=0.0 text:str="" param:SimpleThresholdParam=SimpleThresholdParam() def simple_threshold(srcs:list[np.ndarray], param:SimpleThresholdParam) -> list[np.ndarray]: """cv2.threshold Args: srcs (list[np.ndarray]): _description_ param (SimpleThresholdParam): _description_ Returns: list[np.ndarray]: _description_ """ return [cv2.threshold(src, param.thresh, 255, cv2.THRESH_BINARY)[1] for src in srcs] def simple_threshold_to_string(srcs:list[np.ndarray], param:SimpleThresholdParam, training_text:str, use_only_length:bool=False) -> SimpleThresholdResult: """SimpleThreshold後にOCR Args: srcs (list[np.ndarray]): _description_ param (SimpleThresholdParam): _description_ training_text (str): _description_ use_only_length (bool, optional): _description_. Defaults to False. Returns: SimpleThresholdResult: _description_ """ images = simple_threshold(srcs, param) score, text = image_to_string(images, training_text, use_only_length) return SimpleThresholdResult(score, text, param) SIMPLE_THRESHOLD_PARAM_RANGE = [SimpleThresholdParam(thresh) for thresh in range(1,101)] def get_simple_threshold_param_range() -> list[SimpleThresholdParam]: """SimpleThresholdのパラメータ範囲 Returns: list[SimpleThresholdParam]: _description_ """ return SIMPLE_THRESHOLD_PARAM_RANGE
AdaptiveThreshold
import numpy as np import cv2 from dataclasses import dataclass @dataclass class AdaptiveThresholdParam: block_size:int=3 c:int=1 def adaptive_threshold(srcs:list[np.ndarray], param:AdaptiveThresholdParam) -> list[np.ndarray]: """cv2.adaptiveThreshold Args: srcs (list[np.ndarray]): _description_ param (AdaptiveThresholdParam): _description_ Returns: list[np.ndarray]: _description_ """ return [cv2.adaptiveThreshold(src, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, param.block_size, param.c) for src in srcs] ADAPTIVE_THRESHOLD_PARAM_RANGE = [AdaptiveThresholdParam(block_size, c) for block_size in range(3,12,2) for c in range(1,101)] def get_adaptive_threshold_param_range() -> list[AdaptiveThresholdParam]: """AdaptiveThresholdのパラメータ範囲 Returns: list[AdaptiveThresholdParam]: _description_ """ return ADAPTIVE_THRESHOLD_PARAM_RANGE
HybridThreshold
import numpy as np import cv2 from dataclasses import dataclass from dataclasses_json import dataclass_json from pathlib import Path import json from tesseract_common import image_to_string from simple_threshold import ( SimpleThresholdParam, simple_threshold, get_simple_threshold_param_range, ) from adaptive_threshold import ( AdaptiveThresholdParam, adaptive_threshold, get_adaptive_threshold_param_range, ) @dataclass_json @dataclass class HybridThresholdParam: simple:SimpleThresholdParam=SimpleThresholdParam() adaptive:AdaptiveThresholdParam=AdaptiveThresholdParam() @dataclass_json @dataclass class HybridThresholdResult: score:float=0.0 text:str="" param:HybridThresholdParam=HybridThresholdParam() def hybrid_threshold_to_string(srcs:list[np.ndarray], param:HybridThresholdParam, training_text:str, use_only_length:bool=False) -> HybridThresholdResult: """HybridThreshold後にOCR SimpleThresholdとAdaptiveThresholdの有効ピクセルを採用 Args: srcs (list[np.ndarray]): _description_ param (HybridThresholdParam): _description_ training_text (str): _description_ use_only_length (bool, optional): _description_. Defaults to False. Returns: HybridThresholdResult: _description_ """ simple_images = simple_threshold(srcs, param.simple) adaptive_images = adaptive_threshold(srcs, param.adaptive) hybrid_images = [cv2.min(simple_image, adaptive_image) for simple_image, adaptive_image in zip(simple_images, adaptive_images)] score, text = image_to_string(hybrid_images, training_text, use_only_length) return HybridThresholdResult(score, text, param) def get_hybrid_threshold_param_range(best_path:str="") -> list[HybridThresholdParam]: """SimpleThreshod+AdaptiveThresholdのパラメータ範囲 Bestパラメータファイルが指定されていない場合は全ての組み合わせを返す Returns: list[HybridThresholdParam]: _description_ """ if Path(best_path).is_file(): with open(best_path, mode="r", encoding="utf-8") as f: json_data = json.load(f) return [HybridThresholdParam.from_json(data) for data in json_data] else: return [HybridThresholdParam(simple, adaptive) for adaptive in get_adaptive_threshold_param_range() for simple in get_simple_threshold_param_range()]
Train
from concurrent.futures import ThreadPoolExecutor from dataclasses import dataclass, field import json from operator import attrgetter from argparse_dataclass import ArgumentParser import cv2 from pathlib import Path import numpy as np from tqdm import tqdm from transcript_table import Transcript from simple_threshold import ( simple_threshold_to_string, get_simple_threshold_param_range, SimpleThresholdResult, ) from hybrid_threshold import ( hybrid_threshold_to_string, get_hybrid_threshold_param_range, HybridThresholdResult, ) @dataclass class Config: stage:int=field(metadata=dict(choices=[1,2], help="1:validate_testdata 2:validate_testdata")) transcripts:str=field(metadata=dict(required=True, help="select transcript")) output_path:str=field(metadata=dict(required=True, help="出力結果の保存先")) best_score_threshold:int=field(default=99, metadata=dict(help="ベストスコアの閾値")) image_color_invert:bool=field(default=True, metadata=dict(help="画像の色を反転させる")) ignore_best:bool=field(default=False, metadata=dict(required=True, help="最初のみ最適なパラメータを無視するか")) def load_images(config:Config, images:list[str]) -> list[np.ndarray]: """画像読込 Args: config (Config): _description_ images (list[str]): _description_ Returns: list[np.ndarray]: _description_ """ if config.image_color_invert: return [cv2.bitwise_not(cv2.cvtColor(cv2.imread(image), cv2.COLOR_BGR2GRAY)) for image in images] else: return [cv2.cvtColor(cv2.imread(image), cv2.COLOR_BGR2GRAY) for image in images] def load_transcripts(filename:str) -> list[Transcript]: if Path(filename).is_file(): with open(filename, mode="r", encoding="utf-8") as f: json_data:dict[str,str] = json.load(f) return [Transcript.from_json(data) for data in json_data.values()] def validate_testdata(config:Config): # load transcripts. transcripts = load_transcripts(config.transcripts) # create output_dir. output_path = Path(config.output_path) / "dump" / "validate" output_path.mkdir(parents=True, exist_ok=True) with ThreadPoolExecutor() as executor: for transcript in transcripts: images = load_images(config, transcript.images) futures = [ executor.submit( simple_threshold_to_string, images, param, transcript.training_text, transcript.text!=transcript.training_text, ) for param in get_simple_threshold_param_range() ] success_count:int = 0 results:list[SimpleThresholdResult] = [] with tqdm(futures, desc=f"{transcript.name}", postfix={"Success":success_count}) as iters: for future in iters: result = future.result() results.append(result) success_count += 1 if result.score >= 1.0 else 0 iters.set_postfix({"Success":success_count}) results = sorted(results, key=attrgetter("score"), reverse=True) with open(str(output_path / f"{transcript.name}.json"), mode="w", encoding="utf-8") as f: temp_results = [result.to_json(ensure_ascii=False) for result in results] json.dump(temp_results, f, indent=2, ensure_ascii=False) def train_threshold_parameter(config:Config): # load transcripts. transcripts = load_transcripts(config.transcripts) # create output_dir. output_path = Path(config.output_path) / "dump" / "parameter" output_path.mkdir(parents=True, exist_ok=True) # best param path. best_path = output_path / "best.json" # 0-1 best_score_threshold = config.best_score_threshold / 100 with ThreadPoolExecutor() as executor: for idx, transcript in enumerate(transcripts): # TODO: この除外設定正式に実装したい # できればstage1の結果が一定数未満の場合は自動的に除外設定に入れるような #if transcript.name in ["TEXT013", "TEXT014"]: # continue images = load_images(config, transcript.images) futures = [ executor.submit( hybrid_threshold_to_string, images, param, transcript.training_text, transcript.text!=transcript.training_text, ) for param in get_hybrid_threshold_param_range("" if config.ignore_best and idx == 0 else best_path) ] success_count:int = 0 results:list[HybridThresholdResult] = [] with tqdm(futures, desc=f"{transcript.name}", postfix={"Success":success_count}) as iters: for future in iters: result = future.result() results.append(result) success_count += 1 if result.score >= 1.0 else 0 iters.set_postfix({"Success":success_count}) results = sorted(results, key=attrgetter("score"), reverse=True) # save all result. with open(str(output_path / f"{transcript.name}.json"), mode="w", encoding="utf-8") as f: temp_results = [result.to_json(ensure_ascii=False) for result in results] json.dump(temp_results, f, indent=2, ensure_ascii=False) # save best result. temp_bests = [result.param.to_json(ensure_ascii=False) for result in results if result.score >= best_score_threshold] if len(temp_bests) > 0: with open(str(best_path), mode="w", encoding="utf-8") as f: json.dump(temp_bests, f, indent=2, ensure_ascii=False) else: print(f"\"{transcript.name}\" not found best parameters.") print("") # try with best parameters. best_param = get_hybrid_threshold_param_range(best_path)[0] for transcript in transcripts: images = load_images(config, transcript.images) result = hybrid_threshold_to_string( images, best_param, transcript.training_text, transcript.text!=transcript.training_text ) print(f"{transcript.name}|{result.score:.2f}|{result.text}") def my_app(config:Config): if config.stage == 1: validate_testdata(config) elif config.stage == 2: train_threshold_parameter(config) if __name__ == "__main__": my_app(ArgumentParser(Config).parse_args())
テキストと画像データの読込
@dataclass_json @dataclass class Transcript: name:str="" text:str="" training_text:str="" images:list[str]=field(default_factory=list) def load_transcripts(filename:str) -> list[Transcript]: if Path(filename).is_file(): with open(filename, mode="r", encoding="utf-8") as f: json_data:dict[str,str] = json.load(f) return [Transcript.from_json(data) for data in json_data.values()]
画像とテキストデータの作成フローをツール化しちゃっているためにこのような実装になっていますが、必要なものはテキストと画像データパスの2つだけなのでdict[str,str]等で再現可能です。
画像を読込後 白黒化等の下処理
def load_images(config:Config, images:list[str]) -> list[np.ndarray]: """画像読込 Args: config (Config): _description_ images (list[str]): _description_ Returns: list[np.ndarray]: _description_ """ if config.image_color_invert: return [cv2.bitwise_not(cv2.cvtColor(cv2.imread(image), cv2.COLOR_BGR2GRAY)) for image in images] else: return [cv2.cvtColor(cv2.imread(image), cv2.COLOR_BGR2GRAY) for image in images]
OpenCVで画像を読込後に白黒化をし必要に応じて色反転を行っています。
2値化処理内でもパラメータを指定すればできますが、ここで処理したほうが高速化につながります。
このグレースケール化は何もいじっていないのでガンマ補正等を行う高度なグレースケール化をするとさらに精度が高まる気がします。
validate_testdata
最適なパラメータを見つける前に正常なテストデータかを調べます。
SimpleThresholdのパラメータ範囲を全て試した精度結果が出力されます。全て試すので正解が1つも無いということはあり得ません。その場合は、誤字が含まれているか、そもそもtesseractが未学習な文字の2択に絞られます。こういったデータは修正するか除外をします。
これらが終わってようやく最適なパラメータ探索ができます。
train_threshold_parameter
最適なパラメータ探索の処理です。
コード内のコメント通りです。
demo
step1: 画像とテキストを用意
step2: 最適なパラメータ探索
ここで紹介するstep1はツール化してありますが、ペイントソフトとテキストソフトを使用することで手動対応可能なので必須ではありません。テスト内容が多い場合はツール化をしたほうが作業の効率化につながるのでおすすめです。
step1
ツール起動

撮影範囲を指定
著作権の関係で弊社コーポレートサイトをキャプチャしていますが、実際にはゲーム画面を撮っています。


テキストとトレーニングテキストをセット
キストが画像から抽出されるべき文字列、トレーニングテキストがOCRで識字してほしい箇所の文字列として分けています。


step2
コマンドプロンプトかvscodeからtrainを実行します。
今回はvscodeから実行します。vscodeから実行する際にコマンドプロンプトと同じようにargparseを受け取らせたい場合は、launch.jsonのargsを編集することで出来ます。

まずはstage1を実行してtesseractが絶対に読めない文字を抽出していきます。
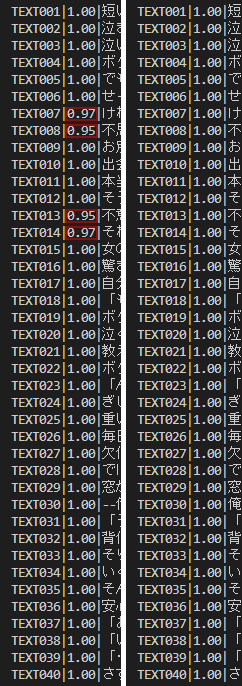
今回のテストデータでは13,14, 24のテキストが読めないようです。
読めない文字を抽出すると「雫、頬、軋」でした。

読めないデータを除外したらstage2を実行します。
ここではゴリゴリにマシンパワーを消費します。

スペックによりますが大体1時間で終わります。

全ての画像を探索し終えるとベストパラメータでのOCR結果を出力されます。
これも公開すると引用に該当しちゃうのでほぼモザイクです。
tesseractが読めない文字が含まれている13,14,24を省いた正解数が34/37なので大体90%ほどの精度です。

tesseract-jpnが未学習な文字
ちょっくら未学習な文字が気になったので調べてみました。
ノベルゲームでよく実装されているモトヤLマルベリ3等幅で対応されている文字のうち未対応なものを抽出してみました。
まずはフォントのバイナリから対応文字のデータを抽出しようと思いましたが、フリーソフトがあったのでおとなしくそちらを使います。
出力結果がこちらです。

かなり幅広く対応していますね。
全てを比較するのは少々無駄な気もするので今回比較する内容は
・Basic Latin(基本ラテン文字)
・Hiragana(ひらがな)
・Katakana(カタカナ)
・CJK Unified Ideographs(CJK統合漢字)
の4つとします。
ちなみにCJK Compatibility Ideographsをtesseract(CJK互換漢字)を学習しようとすると文字列まわりのエンコードエラーが出たので比較対象から外しています。「塚﨑諸館鶴」ここら辺の文字は使いそうなのでちょっと不満です。
それではlangdata_lstmのjpn.training_textから重複文字を削除して差分を見てみましょう。

| 基本ラテン文字 | 完璧 |
| ひらがな | ゑ゛゜ |
| カタカナ | ヮ |
| CJK統合漢字 | たくさん |
結果としてはこのような感じです。
ノベルゲームだと悪ふざけで「ゑ」という文字も使うので正直欲しかったです。
濁点と半濁点は、上半分にあるか、下半分にあるかという判定でも入れないと誤認しちゃいそうなので何となく理解できます。bboxをいじればいけそうですが、そのアルゴリズムは入ってないんでしょうかね。
カタカナの小さい「ヮ」もその流れでしょうか。
そして漢字が壊滅的です。これだと精度以前に実用性の問題が出てきちゃいますね。
fine-tuningで解消はできますが、これだけ多いとスクラッチ学習したほうがマシな気がします。
終わり
お疲れさまでした!!!
今後
テスト動作では大津の結果が悪かったので非採用としたのですが自動算出系は間違いなく便利なはずなのでもう少し詰めてみたいなぁといった気持ちです。
あとはそもそもTesseract-OCRを使い続けるには限界がありそうなので、アルゴリズムを変えるようなリリースがないなら自作しちゃうのもアリかなと思えてきました。
「Googleさんを使えばいいじゃない」と思うかもしれませんが、APIってどうしても不安なんですよねぇ。
Cloud Vision 試してみた
hybrid_thresholdをベストパラメータで処理して、リクエスト数を削減するために行ごとに分けた画像は結合してvision apiに投げてみました。
。。。
なんということでしょう。
精度100%です。
tesseract。。。。。。。。
左はhybrid_thresholdをしないで投げた結果でいくつかミスがあります。
右はhybrid_thresholdを適用してから投げた結果です。
自作してみた